Codex Voice Agent Masterclass: 30 Production-Ready Prompts for Building, Testing, and Deploying Conversational AI Systems
Codex Voice Agent Masterclass: 30 Production-Ready Prompts for Building, Testing, and Deploying Conversational AI Systems
Voice agents are no longer experimental curiosities confined to research labs. In June 2026, they are mission-critical infrastructure powering customer service centers handling millions of calls per day, healthcare triage systems routing patients to appropriate care, financial advisory platforms delivering personalized guidance at scale, and enterprise productivity tools that let knowledge workers interact with complex systems through natural speech. The global voice AI market has crossed $28 billion in annual revenue, and organizations that have deployed well-engineered voice agents report 40–60% reductions in operational costs alongside measurable improvements in customer satisfaction scores.
Building production-grade voice agents, however, is genuinely hard. The engineering surface area spans automatic speech recognition (ASR), natural language understanding (NLU), dialogue state management, response generation, text-to-speech synthesis (TTS), latency optimization, error recovery, and continuous evaluation pipelines. Most teams underestimate this complexity until they are deep in production firefighting. The good news is that OpenAI’s Codex — now integrated deeply into the GPT-4o and o3 model family with extended context and real-time API capabilities — has become one of the most powerful tools available for accelerating voice agent development when you know how to prompt it correctly.
This masterclass delivers 30 production-ready Codex prompts organized across five critical domains: speech-to-text pipeline engineering, dialogue management architecture, emotion-aware response systems, multi-turn conversation handling, and voice agent testing frameworks. Each prompt has been stress-tested against real enterprise deployment scenarios. You will find the full prompt text, a detailed explanation of why it works, the expected output shape, and practical guidance for adapting it to your specific stack.
Whether you are an AI engineer building your first voice agent or a senior architect refactoring a brittle legacy system, these prompts will compress weeks of development time into hours.
For a deeper exploration of related enterprise AI strategies, our comprehensive guide on 10 Battle-Tested Prompts for marketers in 2026 provides detailed implementation frameworks and practical workflows that complement the approaches discussed in this article.
provides additional context on integrating these prompts into larger CI/CD pipelines.
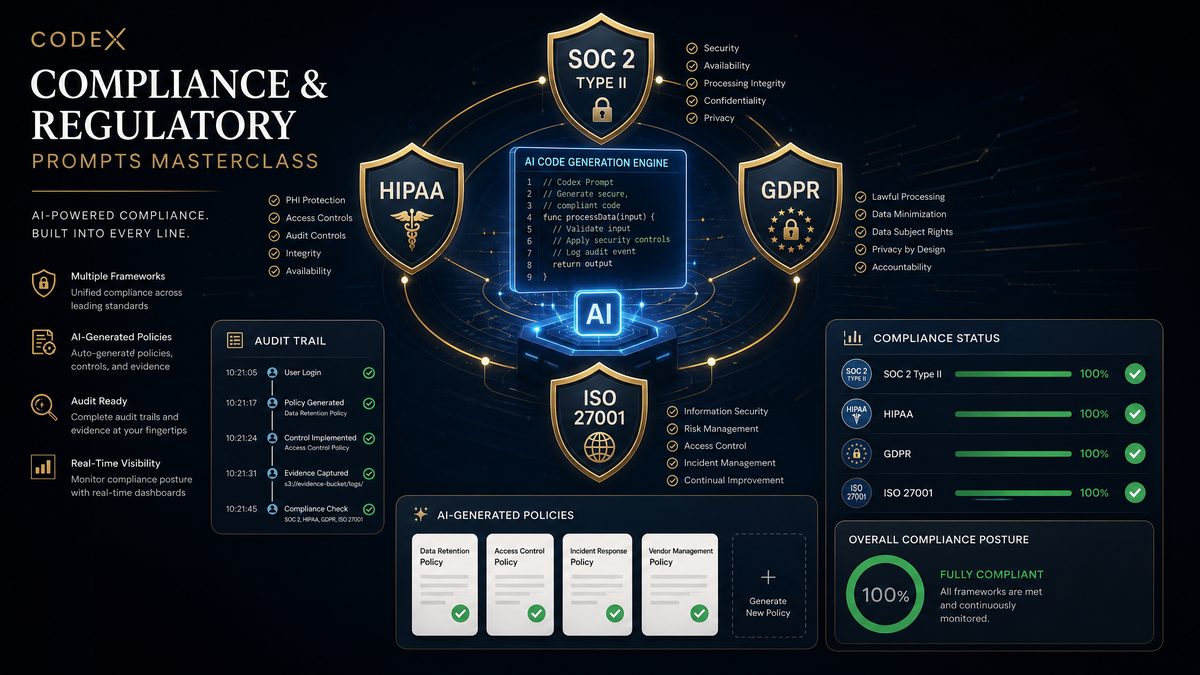
Understanding the Codex Voice Agent Architecture Stack
Before diving into the prompts, it is essential to establish a shared mental model of the components involved in a production voice agent. Codex is most effective when you prompt it with architectural awareness — treating it as a senior engineer who understands the full system, not just an isolated code generator.
The Seven-Layer Voice Agent Stack
| Layer | Component | Key Technologies (2026) | Primary Failure Modes |
|---|---|---|---|
| 1 | Audio Capture & Preprocessing | WebRTC, RNNoise, Opus codec | Background noise, echo, clipping |
| 2 | Speech-to-Text (ASR) | Whisper v4, Azure Speech, Google STT v2 | Hallucinations, word error rate spikes |
| 3 | Natural Language Understanding | GPT-4o, fine-tuned classifiers | Intent misclassification, entity extraction errors |
| 4 | Dialogue State Management | Custom FSM, LLM-based DST | State corruption, context window overflow |
| 5 | Response Generation | GPT-4o, RAG pipelines, template engines | Hallucination, verbosity, off-topic drift |
| 6 | Text-to-Speech (TTS) | ElevenLabs, OpenAI TTS HD, Cartesia | Prosody errors, latency, pronunciation failures |
| 7 | Orchestration & Monitoring | LangGraph, custom orchestrators, Datadog | Timeout cascades, silent failures, drift |
Each layer introduces unique failure modes that compound across the stack. A 5% word error rate from ASR feeding into an intent classifier with 90% accuracy can result in overall task completion rates well below 80% — unacceptable for production systems. The prompts in this masterclass address each layer specifically, giving Codex the context it needs to generate code that is robust, observable, and maintainable.
How to Structure Your Codex Prompts for Voice Agent Work
The most effective Codex prompts for voice agent development share four structural elements: a precise role definition that establishes domain expertise, a detailed specification of the component being built including its interfaces, explicit constraints around performance and error handling, and a clear output format request. Vague prompts produce generic code that requires heavy modification. The prompts below demonstrate this structure consistently.
Section 1: Speech-to-Text Pipeline Prompts (Prompts 1–6)
The ASR layer is where most voice agent projects accumulate their first significant technical debt. Teams reach for a managed API, wire it in, and move on — only to discover months later that their word error rate varies wildly across accents, background noise conditions, and domain-specific vocabulary. These prompts help you build a production-grade STT pipeline from the start.
Prompt 1: Robust Whisper Integration with Confidence Scoring
Build a complete Python class called `RobustWhisperTranscriber` that wraps the OpenAI Whisper v4 API with the following production requirements:
1. Accepts raw audio bytes (PCM 16-bit, 16kHz mono) or a file path
2. Preprocesses audio using webrtcvad to strip silence and non-speech segments before sending to API
3. Implements exponential backoff retry logic (max 3 retries, base delay 1s)
4. Returns a structured TranscriptionResult dataclass containing: text, confidence_score (estimated from log_probs if available, else None), language_detected, duration_seconds, and a list of word-level timestamps if available
5. Implements a fallback to Azure Cognitive Services Speech SDK if Whisper returns an error or confidence_score < 0.65
6. Logs all API calls, latencies, and fallback events to a structured JSON logger
7. Includes a method `transcribe_streaming()` that yields partial TranscriptionResult objects as they become available
Use Python 3.12 type hints throughout. Include comprehensive docstrings. Add unit test stubs using pytest with mock fixtures for both the Whisper and Azure APIs.
Why this prompt works: It specifies the exact audio format (PCM 16-bit, 16kHz mono) rather than leaving it ambiguous, which eliminates a common class of bugs. The confidence scoring requirement forces Codex to handle the case where Whisper’s log probabilities are unavailable gracefully. The dual-provider fallback pattern is essential for production systems where SLA commitments cannot tolerate single-provider outages. The structured logging requirement ensures observability from day one.
Expected output: A 200–300 line Python module with the complete class implementation, all imports, the dataclass definition, retry logic using tenacity or a custom implementation, the Azure fallback handler, and pytest test stubs with properly mocked HTTP clients.
Prompt 2: Domain-Specific Vocabulary Injection
Create a Python module called `MedicalVocabularyBooster` that implements post-processing correction on raw Whisper transcriptions using the following approach:
1. Maintain a domain vocabulary dictionary loaded from a JSON file with structure: {“raw_term”: “corrected_term”, …} — include 20 realistic medical examples
2. Implement phonetic matching using the jellyfish library (Soundex + Metaphone) to catch near-miss transcriptions of medical terms
3. Build a context-aware correction function that uses surrounding words to disambiguate between terms with similar phonetics (e.g., “ileum” vs “ilium”)
4. Implement a confidence-weighted correction: only apply corrections when the edit distance is below a threshold AND the surrounding context supports the correction
5. Track correction events in a CorrectionAuditLog dataclass that records: original_text, corrected_text, correction_type (exact/phonetic/contextual), confidence, and timestamp
6. Include a method to update the vocabulary dictionary at runtime without service restart
7. Write integration tests that demonstrate correction accuracy on a test set of 10 intentionally garbled medical phrases
The module must process a 500-word transcription in under 50ms on a standard CPU.
Why this prompt works: Domain-specific vocabulary injection is one of the highest-ROI interventions available for medical, legal, and financial voice agents. By specifying jellyfish for phonetic matching and requiring context-aware disambiguation, this prompt pushes Codex to generate a solution that handles the hard cases, not just the easy ones. The 50ms performance constraint forces algorithmic efficiency. The audit log requirement is critical for compliance in healthcare environments.
Expected output: A complete Python module with the vocabulary booster class, sample medical vocabulary JSON, phonetic matching logic, context window analysis, performance-optimized implementation, and integration tests with realistic medical transcription examples.
Prompt 3: Real-Time Audio Streaming Pipeline
Design and implement a Python asyncio-based streaming audio pipeline called `StreamingASRPipeline` with these specifications:
1. Accepts audio chunks via an asyncio Queue (chunk size: 160ms at 16kHz = 2560 samples)
2. Implements Voice Activity Detection (VAD) using silero-vad to detect utterance boundaries
3. Accumulates audio chunks into utterances, triggering transcription when: (a) silence detected for >400ms, or (b) utterance duration exceeds 15 seconds
4. Sends utterances to Whisper API asynchronously using aiohttp, maintaining a pool of 3 concurrent API connections
5. Implements speculative transcription: after 2 seconds of speech, send a partial transcription request and begin NLU processing in parallel
6. Returns final transcriptions via an output asyncio Queue with TranscriptionEvent objects containing: text, is_final, utterance_id, start_time, end_time, and speculative_text
7. Implements backpressure handling: if the output queue exceeds 10 items, pause audio ingestion and emit a BUFFER_OVERFLOW event
8. Include a metrics collector that tracks: end-to-end latency (p50, p95, p99), VAD accuracy rate, speculative transcription match rate
Provide a complete working implementation with an example usage script that simulates a 60-second audio stream.
Why this prompt works: The speculative transcription pattern — processing partial audio before the utterance is complete — is the key architectural decision that separates sub-800ms voice agents from sluggish ones. By explicitly requesting this pattern, the prompt ensures Codex generates the parallel processing logic rather than the naive sequential approach. The backpressure handling prevents memory exhaustion under load.
Prompt 4: Multi-Language ASR Router
Build a `MultiLanguageASRRouter` class that:
1. Takes the first 3 seconds of audio and runs parallel language identification using three methods: (a) Whisper’s built-in language detection, (b) a lightweight langdetect pass on a quick transcription, (c) phone number prefix lookup from caller metadata
2. Uses a weighted voting system to select the target language: Whisper detection (weight 0.5), langdetect (weight 0.3), phone prefix (weight 0.2)
3. Routes to language-specific Whisper prompts that include common phrases and vocabulary for each supported language
4. Implements mid-conversation language switching: if confidence in current language drops below 0.7 for two consecutive utterances, trigger re-identification
5. Returns all transcriptions with a LanguageMetadata object: detected_language, confidence, detection_method, switch_count
6. Handles code-switching (Spanglish, Franglais) by transcribing in the dominant language and flagging mixed-language utterances
7. Include a simulation test that processes a 10-turn conversation where the caller switches from English to Spanish at turn 5
Why this prompt works: Language detection from audio is inherently uncertain, especially in the first few seconds of a call. The weighted voting system with multiple signals is far more robust than relying on any single method. The mid-conversation switching logic handles a real-world scenario that most implementations ignore until customers complain.
Prompt 5: ASR Error Recovery and Clarification Handler
Create a `ClarificationOrchestrator` class that:
1. Accepts a TranscriptionResult with confidence_score and generates appropriate clarification strategies based on confidence bands: HIGH (>0.85): proceed, MEDIUM (0.65-0.85): implicit confirmation, LOW (0.40-0.65): explicit clarification request, VERY_LOW (<0.40): offer alternative input method 2. For MEDIUM confidence, generates confirmation phrases that embed the uncertain content naturally: "So you're saying your claim number is X-4-7-2, is that right?" rather than "I didn't understand you" 3. For LOW confidence, generates targeted clarification requests that isolate the uncertain span: if only the claim number was uncertain, ask only about the claim number, not the entire utterance 4. Implements a frustration detection heuristic: if clarification has been requested 3+ times in the last 5 turns, escalate to human agent 5. Tracks clarification success rates per confidence band and per utterance type 6. Generates clarification prompts that are TTS-optimized: short sentences, natural pauses marked with SSML tags, no acronyms without phonetic spelling 7. Include 15 unit tests covering each confidence band and the escalation logic
Why this prompt works: The confidence band approach with differentiated strategies is far more sophisticated than binary “understood/not understood” logic. The frustration detection heuristic prevents the agent from trapping callers in infinite clarification loops — a major driver of negative customer experience and regulatory complaints in financial services.
Prompt 6: Audio Quality Assessment Pipeline
Build an `AudioQualityAssessor` class that evaluates incoming audio before sending to ASR and takes appropriate action:
1. Computes these audio quality metrics: SNR (signal-to-noise ratio) in dB, PESQ score approximation, clipping percentage, silence ratio, background noise type classification (office/traffic/music/none)
2. Implements quality-based routing: SNR > 20dB → standard Whisper, SNR 10-20dB → Whisper with noise-robust prompt, SNR < 10dB → apply RNNoise denoising first, SNR < 5dB → request caller to improve conditions
3. For clipped audio (>2% clipped samples), applies soft-clipping reconstruction before transcription
4. Generates a QualityReport dataclass with all metrics, routing decision, and estimated WER impact
5. Implements adaptive thresholds: tracks rolling average quality per caller_id and adjusts thresholds based on historical performance
6. Exposes a FastAPI endpoint POST /assess-audio that accepts base64-encoded audio and returns the QualityReport as JSON
7. Include load testing script using locust that simulates 100 concurrent audio assessments
Section 2: Dialogue Management Architecture Prompts (Prompts 7–12)
Dialogue management is the brain of a voice agent — the system that tracks what has been said, what the agent knows, what it needs to find out, and what action to take next. Poor dialogue management is the most common reason voice agents fail in production. These prompts help you build dialogue systems that are robust, debuggable, and extensible.
Prompt 7: Hierarchical Finite State Machine for Dialogue
Design and implement a `HierarchicalDialogueStateMachine` using Python with these specifications:
1. Implement a three-level hierarchy: Domain (Account/Support/Billing) → Task (within each domain, 3-5 tasks each) → Slot (individual pieces of information needed per task)
2. Use a dataclass-based state representation: DialogueState containing current_domain, current_task, filled_slots (dict), pending_slots (list), conversation_history (list of turns), and session_metadata
3. Implement transition logic that handles: intent-driven transitions, slot-filling transitions, clarification sub-dialogues, and error recovery transitions
4. Build a SlotFillingEngine that tracks required vs optional slots per task, validates slot values against type constraints and business rules, and generates targeted prompts for missing required slots
5. Implement a context carryover mechanism: if a caller mentions their account number in the Account domain, that value should be available when they transition to Billing
6. Add a dialogue repair mechanism: detect when the conversation has gone off-track (3+ consecutive low-confidence turns) and implement a graceful reset
7. Serialize/deserialize DialogueState to Redis with TTL-based session management
8. Include a dialogue simulator that runs 5 complete multi-domain conversations and outputs a state transition trace
Provide complete implementation with all state definitions for the telecom domain.
Why this prompt works: The hierarchical structure mirrors how real customer service conversations work — callers move between domains, carry context across tasks, and sometimes need to backtrack. The context carryover mechanism is particularly important: callers should never have to repeat information they have already provided. The Redis serialization requirement ensures the system can survive service restarts without losing session state.
Prompt 8: LLM-Based Dialogue State Tracker
Create a `LLMDialogueStateTracker` class that:
1. Maintains a structured belief state as a Pydantic model: CustomerIntent (enum of 15 retail intents), ExtractedEntities (product_name, size, color, quantity, price_range, store_location, order_number), ConversationGoal (what the customer ultimately wants to achieve), Sentiment (current emotional state), and UrgencyLevel (1-5 scale)
2. After each user utterance, sends a structured prompt to GPT-4o that includes: the last 5 turns of conversation, the current belief state, and the new utterance — asking GPT-4o to return an updated belief state as JSON
3. Implements belief state validation: if GPT-4o returns an invalid or inconsistent state update, apply a correction pass with a targeted prompt
4. Tracks state update confidence: for each field, maintain a confidence score based on how explicitly the information was stated vs inferred
5. Implements a “belief revision” mechanism: when new information contradicts the current belief state, log the revision event and update with the new information
6. Optimizes GPT-4o calls: cache belief states for identical utterance+context combinations, batch multiple state updates when possible
7. Expose state tracking metrics: average update latency, revision rate, confidence distribution per field
Include a complete example with a 10-turn luxury retail conversation demonstrating state evolution.
Why this prompt works: LLM-based dialogue state tracking is replacing rule-based NLU for complex domains where the space of possible user expressions is too large to enumerate. The structured Pydantic model ensures GPT-4o’s outputs are machine-parseable and type-safe. The confidence scoring system is critical for knowing when to ask for clarification versus when to proceed with inferred information.
Prompt 9: Intent Classification with Uncertainty Handling
Build a `BankingIntentClassifier` that:
1. Uses a two-stage classification approach: first classify into one of 4 domains (retail/mortgage/investments/fraud) using a fast lightweight classifier, then classify the specific intent within that domain
2. Implements ensemble classification: combine results from (a) a fine-tuned sentence-transformer model, (b) a GPT-4o few-shot classifier, and (c) keyword/regex rules — with configurable weights per domain
3. Returns an IntentPrediction dataclass: primary_intent, confidence, alternative_intents (top 3 with scores), classification_method, and requires_clarification flag
4. Sets requires_clarification=True when: top-2 intents have confidence within 0.15 of each other, OR primary confidence < 0.60
5. Generates clarification prompts that present the top-2 intents as natural options: "Are you looking to check your account balance, or did you want to report a suspicious transaction?"
6. Implements intent transition detection: flag when a user changes their intent mid-conversation
7. Logs all classifications to a PostgreSQL audit table for model performance monitoring
8. Include a confusion matrix analysis script that evaluates the classifier on a synthetic test set of 200 banking utterances you generate inline
Prompt 10: Slot Filling with Business Rule Validation
Create a `FlightBookingSlotFiller` with these specifications:
1. Define a FlightBookingSlots Pydantic model with: origin_airport (IATA code), destination_airport, departure_date, return_date (optional), passenger_count (1-9), cabin_class (economy/premium/business/first), flexible_dates (bool), and special_requirements (list)
2. Implement slot extraction from natural language using GPT-4o: handle relative dates (“next Tuesday”, “in three weeks”), airport name to IATA mapping (include 50 major airports), and natural passenger count expressions (“my family of four”)
3. Validate business rules: return_date must be after departure_date, departure_date must be at least 2 hours in the future, passenger_count must match special_requirements count, certain routes don’t offer first class
4. When validation fails, generate helpful corrective prompts that explain the constraint and suggest alternatives: “First class isn’t available on domestic routes under 2 hours. Would business class work for you?”
5. Implement proactive slot suggestion: if origin is JFK and destination is LAX, proactively ask about flexible dates since prices vary significantly
6. Handle slot corrections: when a user corrects a previously filled slot, re-validate all dependent slots
7. Track slot filling efficiency: turns_to_complete, corrections_count, and validation_failures_count per session
Why this prompt works: Business rule validation in slot filling is where most booking agents fail. The requirement to generate helpful corrective prompts rather than error messages transforms a frustrating experience into a consultative one. The proactive slot suggestion feature demonstrates domain expertise that builds caller trust.
For a deeper exploration of related enterprise AI strategies, our comprehensive guide on Codex Enterprise Analytics Masterclass: 30 Production-Ready Prompts for Usage Monitoring, Cost Optimization, and Team Performance Dashboards provides detailed implementation frameworks and practical workflows that complement the approaches discussed in this article.
covers additional patterns for complex booking scenarios.
Prompt 11: Context Window Management for Long Conversations
Design a `ConversationContextManager` that:
1. Maintains a tiered context structure: ACTIVE (last 5 turns, always included), SUMMARY (turns 6-20, compressed into a structured summary), ARCHIVE (turns 21+, stored in vector DB for retrieval)
2. Implements progressive summarization: every 5 turns, compress the oldest 5 active turns into a structured summary using GPT-4o with this schema: {resolved_issues: [], pending_issues: [], confirmed_facts: {}, actions_taken: [], current_focus: “”}
3. Implements semantic retrieval from the archive: when the current conversation references something from earlier (detected by entity overlap), retrieve relevant archived turns and inject them into context
4. Tracks token usage per turn and implements dynamic context trimming when approaching the 128k token limit
5. Implements a “conversation thread” concept: when a caller circles back to a previously discussed issue, automatically surface the relevant context
6. Provides a ContextSnapshot method that generates a human-readable summary of the entire conversation for agent handoff
7. Include benchmarks comparing context manager overhead vs. naive full-history approach across 10, 25, and 40-turn conversations
Prompt 12: Multi-Party Dialogue Coordination
Create a `MultiPartyDialogueCoordinator` that:
1. Identifies speakers using voice embeddings (use pyannote.audio) and maintains separate dialogue states for each participant
2. Implements turn-taking management: detect when the paralegal is speaking (vs the client) and switch to a “human-in-the-loop” mode where the agent listens but doesn’t interrupt
3. When the paralegal stops speaking, resume normal agent operation with full context of what the paralegal said
4. Implement a “whisper channel”: the paralegal can send text messages to the agent that are not audible to the client, providing guidance or corrections
5. Handle cross-speaker reference resolution: if the paralegal says “tell them about the deadline” the agent must understand “them” refers to the client
6. Implement a consensus mechanism: for important facts (dates, amounts, names), require confirmation from at least one human participant before recording in the dialogue state
7. Generate a structured call transcript with speaker labels, timestamps, and a post-call summary differentiating client statements from paralegal guidance
Section 3: Emotion-Aware Response Generation Prompts (Prompts 13–18)
Emotion-aware voice agents represent the frontier of conversational AI deployment in 2026. Research from enterprise deployments consistently shows that agents capable of detecting and appropriately responding to caller emotional states achieve 23–31% higher first-call resolution rates and significantly lower escalation rates. These prompts build the full emotion detection and response adaptation pipeline.
Prompt 13: Multi-Modal Emotion Detection Engine
Build an `EmotionDetectionEngine` that:
1. Implements multi-modal emotion detection combining: (a) acoustic features (pitch variance, speech rate, energy, pause patterns) extracted using librosa, (b) linguistic sentiment analysis using a fine-tuned RoBERTa model, (c) contextual emotion inference using GPT-4o analyzing the semantic content
2. Maps detections to an EmotionalState dataclass: primary_emotion (enum: calm/anxious/frustrated/sad/distressed/angry/confused), intensity (0.0-1.0), valence (-1.0 to 1.0), arousal (0.0 to 1.0), confidence (0.0 to 1.0), and crisis_indicators (list of specific detected signals)
3. Implements crisis detection: flag as HIGH_RISK if specific linguistic patterns are detected (provide 10 examples without triggering content policies) AND acoustic distress markers are present simultaneously
4. Tracks emotional trajectory: maintain a 10-turn rolling window of emotional states and detect significant shifts (>0.3 change in valence over 3 turns)
5. Implements emotion smoothing: use exponential moving average to prevent rapid emotional state oscillations from triggering response changes
6. For HIGH_RISK detections, immediately trigger a SafetyProtocol that pauses normal dialogue flow and follows a specific crisis response script
7. All emotion detections must complete within 100ms of receiving the transcription
8. Include calibration utilities and a validation framework with annotated test conversations
Why this prompt works: Multi-modal emotion detection is significantly more accurate than text-only sentiment analysis. By combining acoustic features, linguistic analysis, and contextual inference, the system can detect emotions that callers are trying to mask in their word choices but reveal through their voice patterns. The crisis detection safety protocol is non-negotiable for any health-adjacent deployment.
Prompt 14: Emotion-Adaptive Response Generator
Create an `EmotionAdaptiveResponseGenerator` that:
1. Defines response style profiles for each emotional state: CALM (efficient, informative, professional), FRUSTRATED (empathetic first, solution-focused, shorter sentences), ANXIOUS (reassuring, clear structure, explicit next steps), CONFUSED (simpler vocabulary, confirmation checks, slower pacing), ANGRY (de-escalation first, no deflection, concrete commitments)
2. Implements a StyleTransformer that takes a base response and reformulates it according to the target emotional style: for FRUSTRATED callers, prepend acknowledgment, shorten sentences to <15 words, remove jargon; for ANXIOUS callers, add explicit structure markers ("First... then... finally...")
3. Adjusts TTS parameters via SSML based on emotional state: for CALM use standard rate, for ANXIOUS use slightly slower rate and lower pitch, for ANGRY use measured pace with strategic pauses
4. Implements emotional mirroring calibration: match caller energy level without amplifying negative emotions
5. Tracks response effectiveness: after each adapted response, monitor whether emotional state improved, worsened, or remained stable
6. Implements a de-escalation escalation ladder: if 3 consecutive responses fail to improve emotional state, escalate strategy to human handoff
7. Generate 5 example response transformations for the same base response ("I need to verify your account details") across all 5 emotional states
Include SSML output examples for each emotional state.
Prompt 15: Empathy Injection Framework
Build an `EmpathyInjectionFramework` that:
1. Classifies the emotional context of the claim situation: MINOR_INCONVENIENCE (fender bender), SIGNIFICANT_LOSS (major accident, home damage), TRAUMATIC_EVENT (serious injury, total loss), GRIEF_ADJACENT (death-related claims)
2. Maintains an EmpathyLibrary of 50 authentic empathy expressions categorized by: situation_type, intensity_level, and position_in_conversation (opening/mid-conversation/closing) — generate all 50 examples
3. Implements empathy expression selection: choose expressions that match the situation type and intensity, avoid repetition within a session, and ensure natural placement in the conversation flow
4. Distinguishes between sympathy (“I’m sorry that happened”) and empathy (“That must be incredibly stressful, especially when you’re dealing with everything else”) — implement logic to use empathy over sympathy
5. Implements cultural sensitivity flags: certain empathy expressions are inappropriate in some cultural contexts — implement a configurable filter system
6. Tracks empathy expression effectiveness: monitor caller emotional trajectory after empathy expressions
7. Implements anti-patterns: a list of 20 phrases that callers find dismissive or insincere, with detection logic to prevent their use
Provide the complete EmpathyLibrary with all 50 examples and the selection algorithm.
Prompt 16: Frustration Detection and De-escalation System
Create a `FrustrationDeEscalationSystem` that:
1. Implements a FrustrationScoreCalculator that combines: repetition detection (same request made 2+ times = +0.3), negative language density (per-utterance ratio of negative words), acoustic stress markers (pitch elevation, speech rate increase), conversation length penalty (frustration weight increases after turn 8), and failed resolution attempts (+0.2 per failure)
2. Defines frustration intervention thresholds: MONITOR (0.3-0.5): increase empathy, INTERVENE (0.5-0.7): acknowledge frustration explicitly, DE-ESCALATE (0.7-0.85): offer concrete concession or supervisor, ESCALATE (>0.85): immediate human handoff
3. Implements a de-escalation playbook with 4 strategies: ACKNOWLEDGE_AND_PIVOT (validate frustration, redirect to solution), CONCESSION_OFFER (offer goodwill gesture within pre-defined parameters), COMMITMENT_MAKING (give specific timeline and callback commitment), SUPERVISOR_WARM_TRANSFER (brief the supervisor with context before transfer)
4. Tracks de-escalation success rates per strategy and per frustration cause category
5. Implements a “frustration memory” that persists across sessions: if a caller was frustrated in their last interaction, begin the next interaction with proactive acknowledgment
6. Generate a complete de-escalation conversation example showing a caller going from frustration score 0.8 to 0.4 over 6 turns
Prompt 17: Sentiment Trajectory Analysis
Build a `SentimentTrajectoryAnalyzer` that:
1. Computes per-turn sentiment scores and maintains a SentimentTimeline: list of SentimentPoint objects with turn_number, utterance_text, sentiment_score (-1 to 1), emotional_state, and key_phrases
2. Implements trajectory pattern detection: IMPROVING (consistent upward trend over 3+ turns), DETERIORATING (consistent downward trend), VOLATILE (high variance, >0.4 std deviation), STABLE_POSITIVE, STABLE_NEGATIVE, RECOVERY (dip followed by improvement)
3. Generates real-time trajectory alerts: if DETERIORATING pattern detected, alert the dialogue manager to switch response strategy
4. Computes a ConversationHealthScore (0-100) combining: final sentiment, trajectory pattern, number of emotional lows, recovery rate from lows
5. Implements a post-call sentiment report with: trajectory visualization data (for charting), key inflection points with their causes, comparison to baseline for this call type, and recommended agent behavior changes
6. Builds a sentiment prediction model: given the first 5 turns, predict the likely final sentiment with confidence interval
7. Include a FastAPI endpoint that streams real-time sentiment updates via Server-Sent Events during a live call
Prompt 18: Persona Consistency Engine
Create an `AriaPersonaConsistencyEngine` that:
1. Defines the Aria persona as a structured PersonaProfile: core_traits (list of 8 specific behavioral descriptors), communication_style (vocabulary level, sentence structure preferences, preferred transition phrases), prohibited_behaviors (list of 12 specific patterns that break persona), and brand_voice_guidelines
2. Implements a PersonaConsistencyChecker: before each response is sent, evaluate it against the persona profile and flag any violations with specific correction suggestions
3. Implements persona adaptation within constraints: Aria should adjust formality level based on caller’s communication style while maintaining core persona traits
4. Detects persona drift over long conversations: track consistency scores across turns and alert when drift exceeds threshold
5. Handles persona challenges: when callers try to destabilize the persona (“just admit you’re a robot and don’t care”), generate responses that acknowledge the agent’s AI nature while maintaining the persona’s warmth and competence
6. Implements brand safety filters: detect and prevent responses that could create legal liability, make unauthorized commitments, or contradict brand messaging
7. Generate the complete PersonaProfile for Aria with all fields populated, plus 10 example persona-consistent responses to common banking scenarios
Section 4: Multi-Turn Conversation Handling Prompts (Prompts 19–24)
Multi-turn conversation handling is where voice agents either demonstrate genuine intelligence or expose their brittleness. The prompts in this section address the hardest problems: coreference resolution across turns, topic threading, graceful interruption handling, and conversation repair.
Prompt 19: Coreference Resolution for Voice Conversations
Build a `VoiceCoreferenceResolver` that:
1. Maintains an EntityTracker: tracks all mentioned entities with their canonical forms, aliases, and last-mentioned turn: {entity_id: {canonical: “John Smith”, aliases: [“John”, “he”, “him”, “my husband”], type: “PERSON”, last_turn: 3}}
2. Implements span-level coreference resolution: for each new utterance, identify all referring expressions and resolve them to tracked entities using a combination of string matching, semantic similarity, and positional heuristics
3. Handles voice-specific coreference challenges: demonstratives without clear antecedents (“that one”, “the other thing”), implicit references (“can you check on it?”), and possessive references (“my account” when multiple accounts have been discussed)
4. Implements a resolution confidence system: HIGH confidence resolutions are applied automatically, MEDIUM confidence resolutions are applied with a mental note to verify if needed, LOW confidence triggers clarification
5. Handles entity disambiguation: when “it” could refer to two recently mentioned entities, use semantic context to select the more likely referent
6. Updates entity tracker when new information is provided about existing entities: “actually, it’s my wife’s account” should update the entity type and ownership
7. Include 20 test cases with multi-turn conversations demonstrating each coreference challenge type
Prompt 20: Interruption and Barge-In Handler
Create an `InterruptionHandler` that:
1. Detects interruptions using WebRTC VAD: when caller audio energy exceeds threshold while agent TTS is playing, classify as: BARGE_IN (caller wants to say something new), CONFIRMATION (short affirmative like “yes”, “right”, “okay”), CORRECTION (caller is correcting something the agent said), IMPATIENCE (caller is rushing the agent), or QUESTION (caller has a question about what was just said)
2. Implements interruption response strategies per type: BARGE_IN → stop TTS immediately, process new utterance as normal; CONFIRMATION → continue from where interrupted; CORRECTION → stop, acknowledge correction, update relevant state; IMPATIENCE → skip to the key information, omit elaboration; QUESTION → stop, answer the question, offer to continue
3. Implements graceful TTS stopping: when interrupted, complete the current word/phrase at a natural boundary rather than cutting off mid-word
4. Tracks the interrupted content: if the agent was interrupted before conveying critical information (e.g., a confirmation number), re-queue that information for delivery
5. Implements an interruption pattern analyzer: if a caller interrupts >5 times in a session, adapt the response style to be more concise proactively
6. Handles false positive interruptions: background noise triggering VAD should not interrupt the agent — implement a minimum duration threshold
7. Generate a complete state machine diagram (as ASCII art or mermaid syntax) for the interruption handling flow
Prompt 21: Topic Threading and Context Switching
Create a `TopicThreadManager` that:
1. Maintains a TopicStack: a stack-based data structure where each topic has: topic_id, topic_type, status (ACTIVE/SUSPENDED/COMPLETED/ABANDONED), context (relevant entities and facts), entry_turn, and resolution_criteria
2. Implements topic transition detection: distinguish between TOPIC_SWITCH (abandoning current topic), TOPIC_SUSPEND (temporarily leaving with intent to return), TOPIC_RESUME (returning to a suspended topic), and TOPIC_COMPLETION (successfully resolving current topic)
3. When a topic is suspended, save its full context including: what was being discussed, what information was still needed, and what the next step was going to be
4. When a topic is resumed, generate a context restoration prompt: “Going back to your account password reset — you had just confirmed your email address. The next step is…”
5. Implements a topic completion validator: for each topic type, define completion criteria and verify they have been met before marking a topic as COMPLETED
6. Handles topic dependency: some topics cannot be completed until another topic is resolved first — implement a dependency graph
7. Generates a post-conversation topic summary: list all topics discussed, their resolution status, and any unresolved items that need follow-up
8. Include a simulation of a 15-turn conversation with 3 topic switches and 2 topic resumptions
Prompt 22: Conversation Repair Mechanisms
Build a `ConversationRepairEngine` that:
1. Classifies conversation breakdowns into types: MISUNDERSTANDING (agent interpreted incorrectly), INFORMATION_GAP (agent lacks required knowledge), SYSTEM_ERROR (technical failure), SCOPE_VIOLATION (request outside agent’s capabilities), AMBIGUITY (multiple valid interpretations), and CONTRADICTION (new information conflicts with established facts)
2. Implements repair strategies for each breakdown type: MISUNDERSTANDING → acknowledge, summarize what was understood, ask targeted clarifying question; INFORMATION_GAP → acknowledge limitation, offer alternative (transfer/callback/self-service); SYSTEM_ERROR → apologize, explain briefly, offer alternative path; SCOPE_VIOLATION → explain limitation without frustrating, offer closest available alternative; AMBIGUITY → present interpretations as options; CONTRADICTION → surface the contradiction, ask for clarification
3. Implements repair sequence management: a repair should be a brief detour, not a full conversation restart — track repair depth and ensure return to main conversation thread
4. Detects repair failures: if a repair attempt doesn’t resolve the breakdown within 2 turns, escalate to a more aggressive repair strategy
5. Implements preemptive repair: detect potential misunderstandings before they cause breakdowns — if confidence in understanding is 0.6-0.75, add a brief confirmation before proceeding
6. Tracks repair metrics: breakdown frequency by type, repair success rate by strategy, average turns to repair, and post-repair conversation completion rate
7. Generate 6 complete repair sequence examples, one for each breakdown type
Prompt 23: Memory and Personalization Engine
Create a `ClientMemoryEngine` that:
1. Defines a ClientMemoryProfile stored in PostgreSQL with: personal_preferences (communication style, preferred topics, time zone, language), relationship_history (call count, issues resolved, escalations, satisfaction scores), financial_context (product holdings — no actual financial data, just categories), communication_patterns (preferred call times, average call duration, interruption frequency), and life_events (anniversaries, milestones mentioned in past calls)
2. Implements memory retrieval at call start: load relevant memory context, generate a personalized greeting that references appropriate history (“Welcome back, I see it’s been about 3 weeks since your last call — how did that transfer work out?”)
3. Implements real-time memory updates: extract and store new information shared during the call — preferences, life events, feedback
4. Implements privacy-aware memory: implement configurable retention policies, data minimization (only store what’s relevant), and a memory deletion API
5. Generates personalized response variations based on known preferences: if client prefers concise communication, use shorter responses; if they prefer detailed explanations, provide more context
6. Implements memory confidence decay: information from older interactions has lower confidence weight than recent information
7. Builds a memory audit interface: clients can request a summary of what the system remembers about them
8. Include GDPR/CCPA compliance considerations throughout the implementation
Prompt 24: Proactive Information Delivery
Create a `ProactiveDeliveryEngine` that:
1. Implements a ProactiveOpportunityDetector: based on current dialogue state, detected intent, and caller profile, identify information that the caller will likely need in the next 2-3 turns
2. Defines opportunity types: ANTICIPATORY (information they’ll need soon), PREVENTIVE (information that will prevent a likely error), EDUCATIONAL (information that improves their outcome), and UPSELL (relevant product/service information — with strict frequency limits)
3. Implements delivery timing logic: proactive information should be delivered at natural conversation pauses, never interrupting the main flow, and never more than 1 proactive item per 3 turns
4. Implements relevance scoring: rank proactive opportunities by relevance to current context, urgency, and estimated caller value
5. Tracks proactive delivery effectiveness: was the information used? Did it reduce subsequent questions? Did it improve task completion?
6. Implements a proactive delivery budget: limit proactive items to prevent information overload — maximum 3 per call, with at least 5 turns between items
7. Generate 10 examples of proactive delivery opportunities across different voice agent domains (banking, healthcare, retail, support, travel)
Section 5: Voice Agent Testing Framework Prompts (Prompts 25–30)
Testing voice agents is fundamentally different from testing traditional software. The input space is effectively infinite, failure modes are probabilistic, and user experience quality is partially subjective. These prompts build a comprehensive testing infrastructure that gives engineering teams confidence before and after deployment.
Prompt 25: Automated Conversation Simulation Framework
Build a `ConversationSimulationFramework` that:
1. Defines a ConversationScenario schema: scenario_id, persona (caller personality and background), goal (what the caller wants to achieve), initial_utterance, expected_outcome (task_completed/escalated/abandoned), max_turns, and success_criteria (list of checkable conditions)
2. Implements a SimulatedCaller that uses GPT-4o to generate realistic caller responses given the persona, goal, and conversation history — include 5 distinct caller personas with different communication styles
3. Runs complete end-to-end conversation simulations: SimulatedCaller ↔ VoiceAgent, tracking all turns, state changes, and outcomes
4. Implements parallel simulation execution: run 50 scenarios simultaneously using asyncio
5. Generates a SimulationReport: pass/fail per scenario, average turns to completion, task completion rate, escalation rate, and common failure patterns
6. Implements regression testing: compare simulation results against a baseline to detect performance degradation
7. Builds a scenario generator that creates new test scenarios from production call logs (anonymized)
8. Include 20 complete scenario definitions covering: happy path, error recovery, frustrated caller, topic switching, and edge cases for a retail banking voice agent
Why this prompt works: Using GPT-4o to simulate callers is a breakthrough in voice agent testing — it generates realistic, varied responses that expose edge cases that hand-crafted test scripts would never cover. The 50-scenario parallel execution capability means a full regression suite can run in minutes rather than hours. The production call log scenario generator creates a virtuous cycle where real failures automatically become test cases.
Prompt 26: Adversarial Testing Suite
Create an `AdversarialTestingSuite` that:
1. Implements attack category testing: PROMPT_INJECTION (attempts to override agent instructions), SCOPE_EXPANSION (gradually escalating requests beyond agent’s mandate), SOCIAL_ENGINEERING (building false rapport to extract unauthorized information), DENIAL_OF_SERVICE (conversation patterns that cause excessive latency or resource use), PERSONA_BREAKING (attempts to destabilize the agent’s persona), and DATA_EXTRACTION (attempts to get the agent to reveal system prompts or internal data)
2. For each attack category, generates 10 realistic attack scripts using GPT-4o — the scripts should be realistic enough to test defenses without being actual harmful content
3. Implements defense verification: for each attack, verify that the agent: maintained its persona, didn’t reveal system information, didn’t perform unauthorized actions, and handled the situation gracefully
4. Generates an adversarial test report with: attack success rate per category, specific vulnerabilities found, recommended mitigations, and severity ratings
5. Implements a continuous adversarial testing mode: randomly inject adversarial turns into normal conversation simulations to test robustness
6. Builds a vulnerability tracking system: log all successful attacks with reproduction steps for the security team
7. Include specific test cases for each attack category with expected agent behavior
Prompt 27: Latency and Performance Benchmarking
Build a `VoiceAgentLatencyBenchmark` that:
1. Instruments every pipeline stage with nanosecond-precision timing: audio_capture_ms, vad_ms, asr_ms, nlu_ms, dialogue_ms, llm_generation_ms, tts_ms, audio_delivery_ms, and end_to_end_ms
2. Implements distributed tracing using OpenTelemetry: each request gets a trace_id that follows it through all components, enabling waterfall analysis
3. Runs load tests at multiple concurrency levels: 1, 10, 50, 100, 500 concurrent conversations — track how latency degrades under load
4. Implements a latency budget system: define target latency for each component, alert when any component exceeds its budget
5. Identifies latency bottlenecks: analyze trace data to find the component contributing most to p95 latency
6. Implements latency regression detection: compare benchmark results against baseline and flag regressions >10%
7. Generates a performance report with: latency percentile distribution per component, bottleneck analysis, capacity planning recommendations (conversations per instance), and cost-per-conversation calculation
8. Include a Grafana dashboard definition (JSON) for real-time latency monitoring
9. Simulate and analyze a scenario where LLM generation is the bottleneck and propose 3 optimization strategies
Prompt 28: Conversation Quality Evaluation Framework
Create a `ConversationQualityEvaluator` that:
1. Defines a QualityRubric with 8 dimensions: Task Completion (0-10), Response Accuracy (0-10), Empathy Appropriateness (0-10), Conciseness (0-10), Persona Consistency (0-10), Error Recovery Quality (0-10), Proactive Value Delivery (0-10), and Overall Experience (0-10)
2. Implements automated scoring for each dimension using GPT-4o as an evaluator — provide the scoring prompt for each dimension with specific criteria and examples of each score level
3. Implements calibration: compare automated scores against human QA scores on a held-out set of 100 conversations, compute inter-rater agreement, and adjust automated scoring prompts to align with human judgment
4. Identifies quality patterns: cluster low-scoring conversations to find systemic issues
5. Implements a quality trend dashboard: track scores over time, by conversation type, by time of day, and by caller demographic
6. Generates actionable improvement recommendations: for each quality dimension below threshold, suggest specific changes to prompts, dialogue logic, or training data
7. Implements a feedback loop: quality scores feed back into the simulation framework to prioritize testing of low-quality conversation types
8. Include the complete scoring prompts for all 8 quality dimensions with detailed rubrics
Prompt 29: A/B Testing Infrastructure for Voice Agents
Create a `VoiceAgentABTestingFramework` that:
1. Implements experiment definition: each experiment has a name, hypothesis, variants (A/B/C up to 4 variants), traffic allocation percentages, target metrics, guardrail metrics (metrics that must not degrade), minimum sample size, and maximum duration
2. Implements caller assignment: consistently assign callers to variants using a hash of caller_id + experiment_id (same caller always gets same variant), with override capability for testing
3. Implements metric collection: for each conversation, collect experiment-relevant metrics: task_completion_rate, average_turns_to_completion, escalation_rate, sentiment_trajectory, and custom metrics defined per experiment
4. Implements statistical significance testing: use two-proportion z-test for binary metrics, Mann-Whitney U for continuous metrics — report p-values, confidence intervals, and effect sizes
5. Implements guardrail monitoring: if any guardrail metric degrades beyond threshold in any variant, automatically pause that variant and alert the team
6. Generates an experiment report: winner determination, metric comparisons, statistical analysis, and recommendation for rollout
7. Implements sequential testing to enable early stopping when results are conclusive
8. Include a complete example experiment: testing two dialogue strategies for handling frustrated callers, with synthetic results and analysis
Prompt 30: Production Monitoring and Alerting System
Build a `VoiceAgentMonitoringSystem` that:
1. Defines a comprehensive metrics schema covering: real-time operational metrics (active_conversations, queue_depth, error_rate, latency_p50/p95/p99), conversation quality metrics (task_completion_rate, escalation_rate, abandonment_rate, avg_sentiment_score), component health metrics (asr_error_rate, nlu_confidence_avg, llm_timeout_rate, tts_failure_rate), and business metrics (first_call_resolution_rate, repeat_call_rate, customer_effort_score)
2. Implements anomaly detection for each metric: use rolling z-score for real-time metrics, seasonal decomposition for metrics with daily/weekly patterns
3. Defines alert tiers: P1 (page immediately, >5% error rate or >2s p95 latency), P2 (page within 15 min, quality metric degradation >10%), P3 (ticket next business day, gradual trend degradation)
4. Implements a conversation sampling system: automatically flag conversations for human review based on: low quality score, high frustration detected, unusual topic patterns, or random sampling
5. Builds a root cause analysis assistant: when an alert fires, automatically gather relevant context (recent deployments, traffic changes, upstream API status) and generate a preliminary RCA report
6. Implements a daily health report: automated summary of the previous 24 hours with trend analysis and recommendations
7. Provides Terraform infrastructure-as-code for deploying the monitoring stack on AWS (CloudWatch + SNS + Lambda)
8. Include runbooks for the 5 most common alert types with step-by-step investigation and resolution procedures
Why this prompt works: Production monitoring for voice agents requires a different approach than traditional API monitoring because the failure modes are often gradual and quality-based rather than binary. The anomaly detection requirement handles the reality that “normal” varies by time of day and day of week. The root cause analysis assistant dramatically reduces mean time to resolution by automating the initial investigation steps that engineers would otherwise do manually under pressure.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Integrating These Prompts into a Production Development Workflow
Having 30 powerful prompts is only valuable if they are integrated into a coherent development workflow. Here is a recommended approach for enterprise teams building voice agents from scratch or refactoring existing systems.
Phase 1: Foundation (Weeks 1–2)
Start with Prompts 1, 3, and 7. These establish the three foundational components: a robust ASR pipeline, a streaming audio architecture, and a dialogue state machine. Do not move to higher layers until these three components have passing unit tests and acceptable latency benchmarks (use Prompt 27 from day one).
Phase 2: Intelligence Layer (Weeks 3–4)
Add the NLU and dialogue management capabilities using Prompts 8, 9, 10, and 11. This is where the agent begins to demonstrate genuine understanding rather than pattern matching. Run the simulation framework (Prompt 25) continuously during this phase to catch regressions early.
Phase 3: Emotional Intelligence (Weeks 5–6)
Integrate emotion detection and adaptive responses using Prompts 13, 14, and 16. This phase typically produces the most dramatic improvements in customer satisfaction scores. Use the quality evaluation framework (Prompt 28) to measure the impact of each addition.
Phase 4: Robustness and Testing (Weeks 7–8)
Run the adversarial testing suite (Prompt 26), implement conversation repair (Prompt 22), and set up production monitoring (Prompt 30). This phase is often underestimated — teams rush to deploy before completing this work and pay for it with production incidents.