The Codex Application Modernization Playbook: 15 Prompts for Migrating Legacy Systems to Cloud-Native Architecture

The Codex Application Modernization Playbook: 15 Prompts for Migrating Legacy Systems to Cloud-Native Architecture
Type: Prompting Playbook
Introduction
Modernizing a legacy application into a cloud-native architecture is a high-stakes transformation touching code, data, infrastructure, and operating models. While the destination promises elasticity, resilience, and faster change velocity, the journey is complex. This playbook presents a pragmatic, end-to-end approach to harness OpenAI Codex as a force multiplier across your modernization lifecycle. It supplies 15 production-grade prompts—each with context, expected outputs, and validation steps—to accelerate assessments, design decomposition, generate artifacts (Dockerfiles, Kubernetes manifests, CI/CD pipelines), drive data migrations, and establish observability, feature flags, and rollback strategies.
Used correctly, Codex can codify tribal knowledge, standardize patterns, and reduce toil. Used carelessly, it can amplify mistakes. The prompts below embed guardrails, acceptance criteria, and test scaffolds so that each AI-assisted step is reviewable, verifiable, and auditable. You will find concrete examples, code snippets, and checklists you can adapt to your stack and constraints. For deeper background on service boundaries, see
For teams exploring related capabilities, our comprehensive guide on Building AI-Powered Search with GPT-5.5 Instant provides detailed workflows and implementation strategies for building AI-powered search from query understanding to result ranking. The techniques covered there complement the approaches discussed in this article and offer additional depth for practitioners ready to expand their AI toolkit.
. For operational readiness on clusters, see
Organizations implementing these workflows will also benefit from understanding 25 ChatGPT-5.5 Prompts for DevOps Engineers, which covers prompts for CI/CD pipelines and infrastructure as code in detail. The methodologies presented there provide a natural extension of the concepts explored above, particularly for teams scaling their AI-assisted processes.
.
Modernization Principles and Guardrails
Before invoking Codex to generate code, define non-negotiable principles that guide every artifact and decision. These guardrails ensure consistency, security, and operability across teams and waves.
Core Principles
- Value-stream alignment: Decompose along business capabilities and bounded contexts, not arbitrary layers.
- Security by default: Secrets never in code; principle of least privilege; automated scanning in CI.
- Operability first: Each service must have health endpoints, structured logs, traces, metrics, and SLOs.
- Data integrity: Migration steps are reversible, validated, and observable; favor zero-downtime patterns.
- Idempotent automation: Infrastructure, pipelines, and scripts are declarative and repeatable.
- Progressive delivery: Feature flags, canary releases, and blue-green deploys reduce blast radius.
Risk and Control Matrix
| Risk | Control | Owner | Evidence |
|---|---|---|---|
| Data loss during migration | Dual-write with CDC + checksums + revert plan | Data Engineering Lead | Migration run logs, checksum reports |
| Service outage on cutover | Blue/green with health gates and automated rollback | SRE Lead | Deployment pipeline audit trail |
| Security regression | SBOM, SAST/DAST, IaC policy-as-code | Security Architect | CI reports, policy exceptions |
| Performance degradation | Baseline load tests + SLO error budgets | Perf Eng | Load test artifacts, SLO dashboards |
How to Use Codex Effectively in Modernization
Codex accelerates comprehension and generation. Treat it as a pair-programmer with strong pattern recall. Provide concrete inputs (sample files, configs, logs) and explicit outputs (schemas, manifests, tests). Embed acceptance criteria and ask for verification harnesses. Always perform human code review and automated validation before merging.
Inputs Codex Handles Well
- Short to medium code excerpts that exemplify patterns.
- Configuration templates (Dockerfiles, YAML, Terraform, Helm).
- Interface definitions (OpenAPI/Swagger, protobuf, GraphQL SDL).
- Log samples, stack traces, SQL schemas for migration design.
Outputs to Request
- Structured plans (tables, checklists) and code artifacts.
- Test harnesses, validation scripts, health checks.
- Idempotent, parameterized scripts with dry-run modes.
Prompt Hygiene
- State assumptions, constraints, versions, and target platform.
- Define acceptance tests and ask Codex to generate them.
- Iterate: provide diffs and errors; request corrections with context.
Prompt Structure Pattern
Use this structure to keep Codex focused and verifiable.
- Context: Business goal, code snippet, environment, constraints.
- Task: What to produce and in what format.
- Acceptance: Tests, linters, policies it must pass.
- Validation: Ask for self-checks and how to verify locally/CI.
# Template
Context:
- Application: <name>, Domain: <capability>
- Stack: <language/version>, Build: <tooling>, Infra: <cloud/k8s>
- Constraints: <RTO/RPO>, <security>, <SLOs>
- Input: <code/config/sample>
Task:
- Generate <artifact(s)> with comments and parameterization.
- Include <tests/health checks>.
- Output as <files/sections>.
Acceptance:
- Lint passes: <tools>
- Tests pass: <coverage>
- Policies: <OPA/Conftest/Snyk>
Validation:
- Commands to run locally/CI.
- How to roll back if needed.
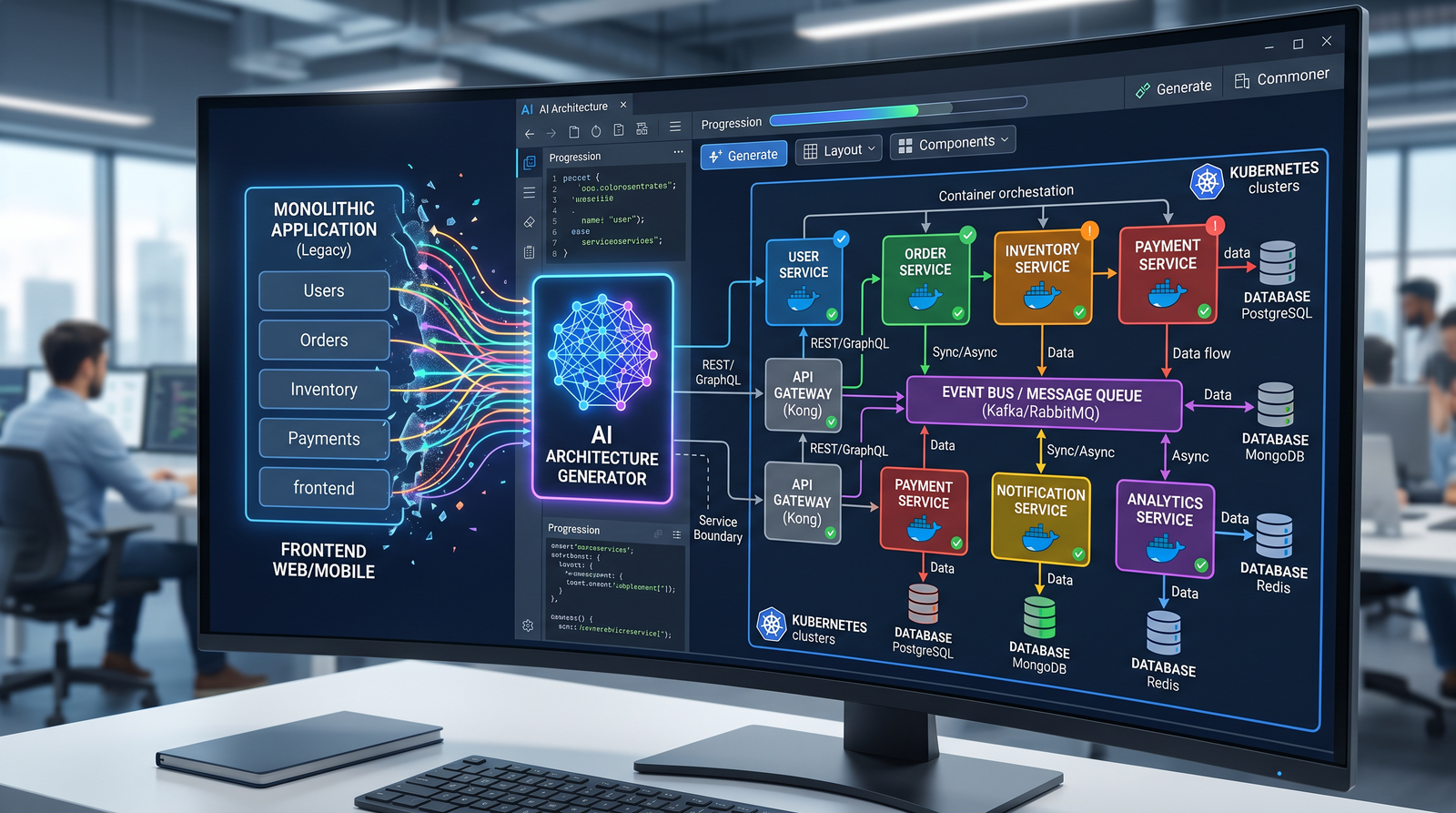
Prompt 1: Legacy Codebase Rapid Assessment
Objective: Produce an actionable summary of a legacy application’s architecture, risks, and quick wins to guide decomposition and migration sequencing.
Context Setup
Provide representative files and metadata: primary language(s), framework versions, build system, deployment topology, and sample logs. Add known pain points (e.g., tight coupling, shared mutable state).
Codex Prompt
Context:
- Codebase: Java 8 monolith (Spring MVC), Maven build
- Repos: single repo, modules: web, service, dao
- Database: Oracle 12c, shared schema
- Infra: on-prem VMs behind F5 LB
- Pain points: shared util with static singletons, long transactions, tight coupling to Oracle sequences
- Input: pom.xml (root), sample Controller, Service, DAO classes, application.properties, 200 lines of app log
Task:
- Produce a 2-page assessment with:
1) Architecture map: modules, dependencies, external systems
2) Risk list with severity and mitigation ideas
3) Modernization opportunities: quick wins (30 days), medium (90 days), long-term
4) Candidate bounded contexts and service seams
- Output as sections with bullets and a summary table.
Acceptance:
- Include explicit evidence references (file names, line ranges).
- Provide a glossary of domain terms extracted from code and logs.
Validation:
- Provide a checklist for a human reviewer to confirm or refine the assessment.
Expected Output
- High-level architecture map and dependency summary.
- Risk/opportunity table with severity and effort.
- Bounded context candidates and seams anchored in code evidence.
- Review checklist for SMEs.
Validation Steps
- Cross-check module dependencies against build graph (e.g., mvn dependency:tree).
- Confirm log-derived domain terms with product owner.
- Hold an SME review to refine bounded context proposals.
Example Table: Risks and Opportunities
| Item | Type | Severity | Effort | Notes |
|---|---|---|---|---|
| Static singletons in util | Risk | High | Low | Replace with DI; breaks tests |
| Introduce health endpoint | Opportunity | Medium | Low | Pre-req for K8s readiness |
| Decouple Oracle sequences | Risk | High | Medium | Use app-level IDs |
Prompt 2: Dependency and Interface Mapping
Objective: Generate a machine-readable map of internal module dependencies and external interfaces (databases, queues, files, third-party APIs) to support service extraction.
Context Setup
Provide build files, package structures, and configuration files that reference external systems: JDBC URLs, message brokers, REST clients, SOAP WSDLs.
Codex Prompt
Context:
- Files: pom.xml, build.gradle (legacy submodule), application.properties/yaml, http client configs
- Languages: Java, Groovy
- External: Oracle (jdbc:oracle:thin), Kafka, SMTP, SOAP (WSDL links)
- Code samples: DAO interfaces, Kafka producer config, REST client wrappers
Task:
- Emit a dependency and interface map as JSON with:
- internalModules: [{name, dependsOn[], packages[]}]
- externalInterfaces: [{type, name, endpoint, protocols, auth, usedByModules[]}]
- dataFlows: [{source, sink, protocol, syncMode, notes}]
- Include a Mermaid diagram snippet for quick visualization.
Acceptance:
- All modules found in build files must appear in the map.
- Endpoints must include environment variable references if present.
Validation:
- Provide jq queries to extract and verify parts of the map.
Expected Output
- JSON dependency map covering internal and external relationships.
- Mermaid diagram for quick team review.
- jq queries for validation.
Validation Steps
# Example jq validations
jq '.internalModules | length' deps.json
jq '.externalInterfaces[] | select(.type=="database") | .endpoint' deps.json
jq '.dataFlows[] | select(.syncMode=="async")' deps.json
Prompt 3: Microservices Decomposition Blueprint
Objective: Propose a decomposition of the monolith into microservices based on domain-driven design (DDD) bounded contexts, team topology, and operational independence.
Context Setup
Feed Codex the dependency map (from Prompt 2), domain glossary (from Prompt 1), and high-change hotspots (from version control history or logs).
Codex Prompt
Context:
- Inputs: deps.json (internal/external map), domain-glossary.md, churn-report.csv (file changes per module)
- Constraints: 2-pizza teams, 4-8 services initial target, minimize cross-context joins
- Non-functional: P99 latency < 300ms for checkout flows
Task:
- Propose service candidates with:
- name, purpose, boundedContext, APIs (coarse), dataOwnership, dependencies
- coupling score (1-5), change rate, team fit
- Output as a table and YAML manifest for tracking (services.yaml).
Acceptance:
- Each service owns its data; shared DB tables must be flagged for split.
- No circular dependencies across proposed services.
Validation:
- Provide a script snippet to detect cycles in the YAML graph.
Expected Output
| Service | Context | Purpose | Data Ownership | Coupling | Change Rate | Team Fit |
|---|---|---|---|---|---|---|
| Catalog | Product | Manage products, attributes | catalog.products, catalog.attributes | 2 | High | Team A |
| Checkout | Order | Cart, pricing, order placement | order.orders, order.items | 3 | Medium | Team B |
Validation Steps
# Example cycle detection pseudocode (Python)
import yaml, sys
g = yaml.safe_load(open('services.yaml'))['services']
edges = {s['name']: s.get('dependsOn', []) for s in g}
seen, stack = set(), set()
def dfs(n):
if n in stack:
print("Cycle at", n); sys.exit(1)
if n in seen: return
stack.add(n)
for m in edges.get(n, []): dfs(m)
stack.remove(n); seen.add(n)
for n in edges: dfs(n)
print("No cycles")
For alternative approaches and deeper examples, refer to
For teams exploring related capabilities, our comprehensive guide on How to Migrate from the OpenAI Assistants API to the Responses API provides detailed workflows and implementation strategies for migrating from Assistants API to Responses API with code examples. The techniques covered there complement the approaches discussed in this article and offer additional depth for practitioners ready to expand their AI toolkit.
.
Prompt 4: Bounded Context and API Contract Extraction
Objective: Extract initial API contracts for each service seam, providing OpenAPI specs with clear request/response models, error codes, and backward compatibility notes.
Context Setup
Provide representative controller classes, DTOs, existing API docs if present, and examples of responses from logs. State versioning strategy (e.g., header-based, URI versioning).
Codex Prompt
Context:
- Controllers: OrderController.java, CartController.java
- DTOs: OrderRequest.java, OrderResponse.java
- Logs: sample 200/400/500 responses
- Versioning: header-based "Accept: application/vnd.acme.order.v1+json"
Task:
- Generate OpenAPI 3.1 specs for Order and Cart services:
- Endpoints, schemas, error models, pagination
- Correlation-ID header required
- Backward-compatibility section with deprecation policy
- Output: order.yaml, cart.yaml
Acceptance:
- Must validate with openapi-cli
- Include examples and schema constraints
- Include standard error structure with traceId
Validation:
- Provide commands to lint and generate server stubs
Expected Output
# order.yaml excerpt
openapi: 3.1.0
info:
title: Order API
version: 1.0.0
paths:
/orders:
post:
summary: Create order
parameters:
- in: header
name: X-Correlation-ID
required: true
schema: { type: string }
requestBody:
content:
application/json:
schema: { $ref: '#/components/schemas/OrderRequest' }
responses:
'201':
description: Created
content:
application/json:
schema: { $ref: '#/components/schemas/OrderResponse' }
'400':
description: Validation error
content:
application/json:
schema: { $ref: '#/components/schemas/Error' }
components:
schemas:
Error:
type: object
required: [code, message, traceId]
properties:
code: { type: string }
message: { type: string }
traceId: { type: string }
Validation Steps
# Validate and stub
npx @redocly/cli lint order.yaml
openapi-generator generate -i order.yaml -g spring -o order-service-stub
Prompt 5: Data Domain Modeling and Monolith-to-Distributed Migration Plan
Objective: Transform the monolithic data model into service-owned schemas with a migration plan that prevents broken joins and preserves referential integrity.
Context Setup
Provide the legacy database schema (DDL), ER diagrams if available, a list of heavy queries, and expected data volumes and growth. Identify tables that different modules rely on.
Codex Prompt
Context:
- Legacy DB: Oracle 12c, schema: ACME_APP
- Inputs: export_ddl.sql, top_queries.sql (AWR), referential_diagram.png (summary)
- Goal: Split into schemas: catalog, order, customer; long-term Postgres on managed service
- Constraints: zero downtime, 2TB total, 50k TPS reads, 2k TPS writes
Task:
- Produce:
1) Target service data models (Postgres DDL) for catalog, order, customer
2) Mapping of legacy tables->service ownership, including bridge tables to be dissolved
3) Data access anti-patterns to refactor (shared sequences, cross-schema joins)
4) Stepwise migration plan with read-only mirrors, CDC, backfill
- Output: data-plan.md, postgres-ddl/*.sql
Acceptance:
- Include primary keys and indexes tuned for top queries
- Referential integrity via foreign keys or application-level ids
- Each migration step contains success metrics and rollback preconditions
Validation:
- Provide SQL to validate row counts and referential integrity post-migration
Expected Output
-- postgres-ddl/order.sql excerpt
CREATE TABLE orders (
id TEXT PRIMARY KEY,
customer_id TEXT NOT NULL,
status TEXT NOT NULL CHECK (status IN ('NEW','PAID','SHIPPED','CANCELLED')),
total_cents BIGINT NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
CREATE INDEX idx_orders_customer_id ON orders(customer_id);
Validation Steps
-- Count parity checks
SELECT COUNT(*) FROM legacy.orders_legacy;
SELECT COUNT(*) FROM order_service.orders;
-- Foreign key integrity (if enforced)
SELECT COUNT(*) FROM order_items oi LEFT JOIN orders o ON o.id = oi.order_id WHERE o.id IS NULL;
-- Performance baseline (explain analyze on hot queries)
EXPLAIN ANALYZE SELECT * FROM orders WHERE customer_id = 'C123' ORDER BY created_at DESC LIMIT 50;
Prompt 6: Database Refactoring and CDC Strategy
Objective: Define the change data capture (CDC) approach and scripts to incrementally replicate and transform data from the monolith database to service databases, with dual-write or dual-read patterns as needed.
Context Setup
Provide information about DB logs access, candidate CDC tools (e.g., Debezium, GoldenGate), and target storage. Include constraints: network bandwidth, security, and consistency expectations.
Codex Prompt
Context:
- Source: Oracle 12c; Target: Postgres 15
- CDC: Prefer Debezium on Kafka
- Security: TLS in transit, secrets from Vault
- Constraints: Eventual consistency acceptable (sub-second), full backfill overnight
Task:
- Generate:
- Debezium connector configs (Oracle source, Postgres sink)
- Topic naming conventions and schema registry strategy
- Transformation examples (SMT) for key mapping and denormalization
- Dual-read gremlin: how to toggle read path via feature flag
- Output: cdc/connectors/*.json, cdc/smt/*.json, doc/cdc-guide.md
Acceptance:
- Configs parameterized via env vars; no secrets hardcoded
- Replay and reprocessing guidance documented
Validation:
- Docker Compose to spin up Kafka + connectors locally for a dry run
Expected Output
{
"name": "oracle-orders-connector",
"config": {
"connector.class": "io.debezium.connector.oracle.OracleConnector",
"tasks.max": "1",
"database.hostname": "${ORACLE_HOST}",
"database.port": "1521",
"database.user": "${ORACLE_USER}",
"database.password": "${ORACLE_PASSWORD}",
"database.dbname": "${ORACLE_SID}",
"topic.prefix": "cdc.oracle.orders",
"schema.include.list": "ACME_APP",
"table.include.list": "ACME_APP.ORDERS,ACME_APP.ORDER_ITEMS",
"transforms": "unwrap,keys",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.keys.type": "org.apache.kafka.connect.transforms.ValueToKey",
"transforms.keys.fields": "ID"
}
}
Validation Steps
# Local test via Docker Compose
docker compose up -d zookeeper kafka connect postgres
curl -X POST -H "Content-Type: application/json" --data @cdc/connectors/oracle-orders.json http://localhost:8083/connectors
# Insert in Oracle; verify messages; confirm Postgres sink receives transformed records
Prompt 7: API Gateway and Edge Architecture Generation
Objective: Define the ingress and API gateway layer, including routing, rate limiting, authentication, and observability with request/response logging safeguards.
Context Setup
Provide platform choices (e.g., NGINX Ingress + Kong/Apigee/Traefik), identity provider (OIDC), and SLO targets. Add required cross-cutting concerns: CORS, mTLS, header propagation.
Codex Prompt
Context:
- K8s: EKS 1.27, NGINX Ingress, Kong Gateway OSS
- Identity: OIDC (Auth0), scopes per service
- Requirements: rate limit per API key, correlation ID, request/response size caps, gRPC support
Task:
- Generate:
- NGINX Ingress objects for /catalog, /order, /customer
- Kong declarative config (routes, services, plugins: OIDC, rate-limit, zipkin)
- Header propagation and error mapping strategy
- Output: k8s/ingress/*.yaml, kong/kong.yaml, doc/edge-arch.md
Acceptance:
- No secrets in YAML; reference K8s Secrets
- Health/ready endpoints excluded from auth and rate limits
- Include Zipkin/Jaeger tracing headers
Validation:
- kubectl commands to apply in a non-prod cluster and smoke tests with curl
Expected Output
# kong/kong.yaml excerpt
_format_version: "3.0"
services:
- name: order
url: http://order.svc.cluster.local:8080
routes:
- name: order-route
paths: [/order]
methods: [GET, POST]
plugins:
- name: oidc
config:
client_id: ${OIDC_CLIENT_ID}
client_secret: ${OIDC_CLIENT_SECRET}
discovery: https://<tenant>.auth0.com/.well-known/openid-configuration
- name: rate-limiting
config:
minute: 600
- name: zipkin
config:
http_endpoint: http://zipkin:9411/api/v2/spans
header_type: preserve
Validation Steps
kubectl apply -f k8s/ingress/
deck sync -s kong/kong.yaml
curl -H "Authorization: Bearer <token>" -H "X-Correlation-ID: test-123" https://api.example.com/order/health
Prompt 8: Containerization (Docker) and Kubernetes Manifests
Objective: Generate production-grade Dockerfiles, multi-stage builds, and Kubernetes manifests with liveness/readiness probes, resource requests/limits, and secret management.
Context Setup
Provide app build process, runtime dependencies, environment variables, and operational requirements (startup time, health checks). State base image policies and registry.
Codex Prompt
Context:
- App: Java 17 Spring Boot (Order Service)
- Build: Maven, Jib or Docker multi-stage
- Policies: Use distroless or alpine base, non-root user
- Secrets: DB URL, username, password via K8s Secrets
- Observability: Expose /actuator/health, /actuator/metrics
Task:
- Create:
- Dockerfile (multi-stage), kubernetes deployment, service, configmap, secret references
- HorizontalPodAutoscaler (HPA) based on CPU and RPS metric
- Output: docker/Dockerfile, k8s/deployment.yaml, k8s/service.yaml, k8s/hpa.yaml
Acceptance:
- Image runs as non-root, read-only FS
- Probes configured and resource limits set
- Works with externalized configs via ConfigMap/Secret
Validation:
- Commands to build, scan, and deploy on a dev cluster
Expected Output
# docker/Dockerfile excerpt
FROM maven:3.9-eclipse-temurin-17 AS build
WORKDIR /src
COPY pom.xml .
RUN mvn -q -B -e -DskipTests dependency:go-offline
COPY . .
RUN mvn -q -B -DskipTests package
FROM gcr.io/distroless/java17-debian11
USER 10001
WORKDIR /app
COPY --from=build /src/target/order.jar /app/order.jar
ENV JAVA_TOOL_OPTIONS="-XX:+UseContainerSupport -XX:MaxRAMPercentage=75"
EXPOSE 8080
ENTRYPOINT ["java","-jar","/app/order.jar"]
Validation Steps
# Build and scan
docker build -t registry.example.com/order:dev -f docker/Dockerfile .
trivy image registry.example.com/order:dev
# Deploy to dev
kubectl apply -f k8s/
kubectl rollout status deploy/order
kubectl logs -l app=order --tail=100
Prompt 9: CI/CD Pipeline Generation with Security Gates
Objective: Provide a CI/CD pipeline that builds, tests, scans, signs, and deploys services with policy-as-code controls and environment promotions via pull requests.
Context Setup
Specify the CI system (GitHub Actions/GitLab CI/Jenkins), required scanners (SAST, SCA, container scan, IaC), signing (Sigstore/Cosign), and deployment strategy (canary/blue-green).
Codex Prompt
Context:
- CI: GitHub Actions
- Scanners: CodeQL, Snyk, Trivy
- IaC Policy: OPA/Conftest on K8s manifests
- Signing: Cosign keyless
- Deploy: Argo CD with canary via Argo Rollouts
Task:
- Generate .github/workflows/ci.yml and cd.yml:
- Build/test, SBOM, scans, sign image, push to registry
- Generate kustomize overlay per env and create PR to Argo repo
- Gates: block merge if critical vulns or policy violations
- Output: workflows, kustomize templates, docs
Acceptance:
- Reusable actions with caching
- Secrets via OIDC, no static tokens in code
Validation:
- Commands to run workflow locally (act) and expected artifacts
Expected Output
# .github/workflows/ci.yml excerpt
name: CI
on:
pull_request:
push:
branches: [ main ]
jobs:
build-test-scan:
runs-on: ubuntu-latest
permissions:
contents: read
id-token: write
packages: write
security-events: write
steps:
- uses: actions/checkout@v4
- uses: actions/setup-java@v4
with: { distribution: temurin, java-version: '17' }
- name: Build
run: mvn -B -DskipTests=false verify
- name: SBOM
run: mvn org.cyclonedx:cyclonedx-maven-plugin:makeAggregateBom
- name: Trivy image scan
run: trivy image --exit-code 1 --severity CRITICAL,HIGH $IMAGE
- name: Cosign sign
run: cosign sign --yes $IMAGE
Validation Steps
# Local dry run
act -j build-test-scan
# Verify policy checks
conftest test k8s/ -p policy/
For templates and opinionated patterns, see
For teams exploring related capabilities, our comprehensive guide on Building AI-Powered Search with GPT-5.5 Instant provides detailed workflows and implementation strategies for building AI-powered search from query understanding to result ranking. The techniques covered there complement the approaches discussed in this article and offer additional depth for practitioners ready to expand their AI toolkit.
.
Prompt 10: Observability Instrumentation (Tracing, Metrics, Logs)
Objective: Instrument services with OpenTelemetry for distributed tracing, metrics (RED/USE), and structured logs to meet SLOs and accelerate incident response.
Context Setup
Provide the application framework, existing logging libraries, and tracing backends (Jaeger/Tempo/Zipkin), metrics stack (Prometheus), and log pipeline (ELK/Loki). Define correlation header names.
Codex Prompt
Context:
- Framework: Spring Boot 3.x
- OTEL: Collector sidecar or DaemonSet, Export to Tempo
- Metrics: Prometheus scrape; SLO: p99 < 300ms, error rate < 1%
- Logs: JSON to Loki via promtail
- Correlation: X-Correlation-ID
Task:
- Add:
- OpenTelemetry SDK config, auto-instrumentation
- Custom spans around order creation and payment calls
- Micrometer metrics: http_server_requests, business counters
- Logback JSON encoder with correlation id
- Output: code snippets, application.yaml additions, collector config
Acceptance:
- No sensitive fields in logs; redact PII
- Traces propagate across async boundaries
Validation:
- curl scripts to verify trace IDs end-to-end; PromQL for key SLOs
Expected Output
# application.yaml additions
management:
tracing:
enabled: true
endpoints:
web:
exposure:
include: health,metrics,info,prometheus
# Custom span example (Kotlin/Java-like)
val span = tracer.spanBuilder("OrderService.createOrder").startSpan()
try {
span.setAttribute("customer.id", customerId)
// business logic
} finally {
span.end()
}
Validation Steps
# Verify SLO metrics
sum(rate(http_server_requests_seconds_count{status!~"5.."}[5m]))
/ sum(rate(http_server_requests_seconds_count[5m]))
# Verify logs carry correlation-id
kubectl logs deploy/order | jq 'select(.correlationId != null)'
Prompt 11: Data Migration Scripts and Validation Harness
Objective: Generate idempotent, resumable data migration scripts with checksum verification and a validation harness to compare legacy and target datasets.
Context Setup
Provide table mappings from Prompt 5, CDC approach from Prompt 6, and SLAs for migration windows. Include data quality rules and PII handling requirements.
Codex Prompt
Context:
- Mapping: orders -> order.orders; order_items -> order.items
- Window: 8 hour backfill, continuous CDC after
- Quality rules: totals match; statuses within enum; no orphan items
- PII: redact email, phone in logs
Task:
- Create:
- Backfill script (Go or Python) with batching, retry, checkpoints
- Checksums per batch; end-to-end reconciliation report
- Dry-run mode and circuit breaker on error rate
- Output: migrate/backfill.py, migrate/lib/*.py, migrate/validate.sql, README.md
Acceptance:
- Idempotent: safe to re-run with same checkpoint
- Time-bounded batch sizes and concurrency settings
- Structured JSON logs for audit
Validation:
- Commands to simulate failures and resume; sample reports
Expected Output
# migrate/backfill.py excerpt
import json, time
BATCH_SIZE = int(os.getenv("BATCH_SIZE", "5000"))
def process_batch(offset):
rows = src.fetch_orders(offset, BATCH_SIZE)
for r in rows:
tgt.upsert_order(transform(r))
csum = checksum(rows)
state.save(offset + len(rows), csum)
print(json.dumps({"event": "batch_done", "offset": offset, "checksum": csum}))
Validation Steps
# Dry run
DRY_RUN=1 python migrate/backfill.py
# Simulate failure and resume
python migrate/backfill.py & sleep 5; kill %1
python migrate/backfill.py --resume
# Reconciliation
psql -f migrate/validate.sql
Prompt 12: Feature Flags and Progressive Delivery
Objective: Introduce feature flags to decouple deployment from release, enabling dark launches, canaries, and rapid rollback by configuration.
Context Setup
Provide the target feature flag SDK (e.g., OpenFeature), environments, and rollout policies. Identify high-risk features where flags will mitigate risk during cutover.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Codex Prompt
Context:
- SDK: OpenFeature (Java)
- Flags: enable_new_pricing, read_from_new_db
- Envs: dev, staging, prod
- Rollout: 5% - 25% - 50% - 100% with SLO guards
Task:
- Generate:
- Initialization code, flag evaluation helpers
- Example usage in service methods
- Configuration files per env
- Runbook for promotion and rollback via flags
- Output: src/main/java/.../FeatureFlags.java, config/flags/*.yaml, doc/feature-flags.md
Acceptance:
- Default safe values; fail-closed behavior
- Metrics on flag evaluation to inform rollout
Validation:
- Unit tests that assert behavior with flags on/off
Expected Output
// FeatureFlags.java excerpt
public class FeatureFlags {
private final Client client;
public boolean newPricingEnabled(String customerId) {
return client.getBooleanValue("enable_new_pricing", false,
EvaluationContext.builder().targetingKey(customerId).build());
}
}
Validation Steps
# Example unit test
assertFalse(flags.newPricingEnabled("custA"));
setFlag("enable_new_pricing", true, targeting="custA");
assertTrue(flags.newPricingEnabled("custA"));
Prompt 13: Resilience, Timeouts, and Retries Policy
Objective: Define and implement service-level resilience patterns including timeouts, retries with backoff, circuit breakers, and bulkheads with clear defaults and overrides.
Context Setup
Provide service-to-service latency budgets, idempotency characteristics of operations, and libraries available (Resilience4j, Envoy, service mesh policies).
Codex Prompt
Context:
- Mesh: Istio; App: Java Spring Boot; Client: WebClient
- Latency budget: 300ms p99; upstream timeouts: catalog 200ms, payment 1s
- Idempotency: order creation not idempotent unless idempotency-key provided
Task:
- Provide:
- Resilience4j config for timeouts, retries, circuit breaker
- Istio VirtualService with outlier detection and retry policy
- Idempotency-key middleware patterns
- Output: application.yaml, ResilienceConfig.java, k8s/istio/*.yaml, doc/resilience.md
Acceptance:
- Retries only on idempotent endpoints and safe error codes
- Timeouts enforce budget; no retry storms
Validation:
- Chaos tests: inject latency/errors and observe behavior
Expected Output
# application.yaml excerpt
resilience4j:
retry:
instances:
catalog:
max-attempts: 2
wait-duration: 50ms
retry-exceptions:
- java.io.IOException
timelimiter:
instances:
catalog:
timeout-duration: 200ms
Validation Steps
# Fault injection (Istio)
kubectl apply -f k8s/istio/fault-injection.yaml
# Observe metrics and ensure SLO budgets hold
Prompt 14: Rollback and Disaster Recovery Playbook
Objective: Prepare executable rollback procedures and disaster recovery (DR) runbooks that combine infrastructure, data, and application layers with RTO/RPO guarantees.
Context Setup
Document RTO/RPO, critical systems, and dependencies. Provide current backup/restore tooling, infra-as-code, and replication topology.
Codex Prompt
Context:
- RTO: 30 minutes; RPO: 5 minutes
- Infra: Terraform, EKS, managed Postgres with cross-region replicas
- Backups: Nightly full + WAL shipping
- Deployment: Argo CD with app-of-apps
Task:
- Produce:
- Rollback runbook for application versions and DB schema changes
- DR failover steps (region A -> region B)
- Terraform/automation scripts to validate DR environment weekly
- Output: runbooks/rollback.md, runbooks/dr.md, scripts/dr-verify.sh
Acceptance:
- Clear decision tree with SLO guardrails and checkpoints
- Data integrity verification after rollback/failover
- Contacts and escalation paths included
Validation:
- Game day scenario with stopwatch-based time capture
Expected Output
# scripts/dr-verify.sh excerpt
set -euo pipefail
kubectl --context=dr get pods -A
psql "$PGURL" -c "select now(), count(*) from orders"
curl -fsS https://dr.api.example.com/healthz
Validation Steps
- Run quarterly DR game days with randomized failure injectors.
- Capture actual RTO/RPO; feed back into capacity and replication settings.
Prompt 15: Cutover Runbook and Post-Migration Hardening
Objective: Define a step-by-step cutover play with clear checkpoints, communication templates, and post-migration hardening activities.
Context Setup
Provide all preceding artifacts: APIs, data migration status, feature flag configuration, readiness and smoke tests, and SLO dashboards. Include stakeholder list and blackout windows.
Codex Prompt
Context:
- Services: catalog, order, customer; APIs stable; data backfill complete; CDC running
- Flags: read_from_new_db=false (default)
- Observability: Dashboards ready; alerting tuned
- Stakeholders: SRE, App Owners, Support, Security, Product
Task:
- Generate:
- Cutover checklist (T-7 days to T+7 days)
- Communication plan with templates (Slack, email, status page)
- Post-migration hardening: rate limits, WAF rules, SLO tuning, backups, cost monitoring
- Output: runbooks/cutover.md, comms/templates.md, hardening/checklist.md
Acceptance:
- Rollback decision gates at each checkpoint
- Clear owners and timestamps; one-click scripts where possible
Validation:
- Tabletop exercise; link to evidence (PRs, dashboards)
Expected Output
| Phase | Action | Owner | Go/No-Go Criteria |
|---|---|---|---|
| T-1h | Freeze monolith writes; enable dual-write | Data Eng | Error rate below 0.5%, lag under 2s |
| T | Flip read_from_new_db to 10% | SRE | p95 latency < 200ms, no 5xx spike |
| T+30m | Increase to 50% if healthy | SRE | All SLOs green |
| T+1d | Decommission monolith path | App Owner | Zero fallbacks in 24h |
Validation Steps
- Rehearse in staging with production-like load and data.
- Run parallel error budgeting to qualify production readiness.
- Confirm feature flag overrides for immediate rollback paths.
Midpoint Checkpoint: Governance and Risk
At the midpoint of a modernization program—after initial assessments, decomposition, and early service deployments—revisit governance, risk, and compliance. Ensure policy-as-code is active in CI/CD, SLOs are adopted, and data migration metrics are visible. Validate your program charter against business outcomes and adjust the backlog accordingly.
Key Questions
- Are service boundaries enforcing data ownership without shared database access?
- Do SLOs align with customer expectations and incident response playbooks?
- Are secrets, SBOMs, and vulnerability scans enforced on every build?
- Is a rollback plan proven via drills and does it meet RTO/RPO?
Governance Check Table
| Control | Evidence | Status | Owner |
|---|---|---|---|
| IaC policy checks | Conftest reports in CI | Green | Platform Eng |
| Runtime security | Admission controller logs | Yellow | Security |
| Observability baseline | Dashboards per service | Green | SRE |
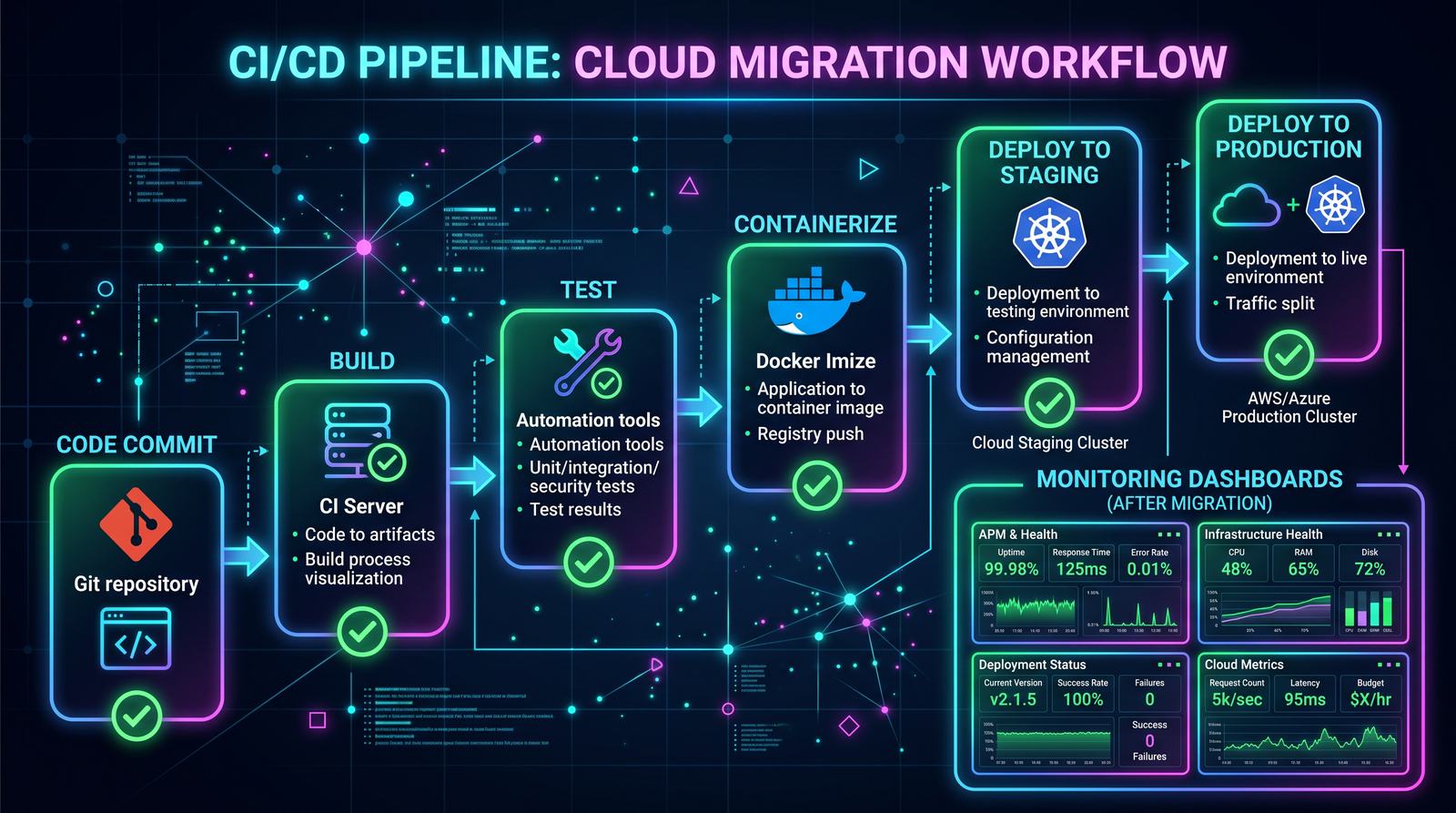
Migration Waves and Execution Plan
Create migration waves that deliver end-to-end capability slices, not layers. Each wave should include service extraction, data migration, CI/CD, and observability for that slice. Track dependencies and ensure that shared components are stabilized.
Wave Planning Table
| Wave | Capability | Services | Data Scope | Risks | Exit Criteria |
|---|---|---|---|---|---|
| Wave 1 | Catalog Browsing | Catalog | Products, Attributes | Cache coherency | 95% cache hit, zero stale complaints |
| Wave 2 | Cart and Checkout | Cart, Pricing, Order | Orders, Items | Payment gateway reliability | SLO met for 2 weeks |
| Wave 3 | Customer Accounts | Customer, Notification | Profiles, Preferences | PII handling | Security review passed |
Critical Path Management
- Resolve shared database hotspots before extraction.
- Parallelize where boundaries are clear; serialize where coupling is high.
- Integrate performance testing and security scanning into every wave.
Tooling and Environment Baselines
Standardize your modernization toolkit across teams to reduce cognitive load and variance. Define golden paths and templates in a platform engineering repository, with guardrails and documentation.
Baseline Tooling Matrix
| Category | Tooling | Policy | Notes |
|---|---|---|---|
| Containers | Docker, BuildKit, Distroless | Non-root, read-only FS | Use base image from internal registry |
| Orchestration | Kubernetes, Argo CD, Helm/Kustomize | GitOps-only changes | Admission policies enforced |
| CI/CD | GitHub Actions, Cosign | SBOM + scan gates | OIDC for secretless auth |
| Observability | OpenTelemetry, Prometheus, Loki, Tempo | Dashboards per SLO | Sample rate adaptive |
| Security | CodeQL, Snyk, Trivy, OPA | Block on criticals | Daily baseline scans |
Golden Repository Structure
platform-templates/
service-skeleton/
docker/
k8s/
workflows/
docs/
policies/
opa/
conftest/
examples/
order-service/
catalog-service/
Align this with your platform charter and internal developer portal. Surface templates and paved roads so teams can create compliant services quickly. For operational guidance, see
Organizations implementing these workflows will also benefit from understanding 25 ChatGPT-5.5 Prompts for DevOps Engineers, which covers prompts for CI/CD pipelines and infrastructure as code in detail. The methodologies presented there provide a natural extension of the concepts explored above, particularly for teams scaling their AI-assisted processes.
.
Conclusion and Next Steps
This playbook provides a practical, verifiable approach to cloud-native modernization using Codex as an accelerator. The 15 prompts, when executed with clear inputs and acceptance criteria, generate artifacts that are auditable and production-ready—from initial assessments through to cutover and hardening. Treat Codex outputs as drafts to be reviewed, tested, and enforced via policy and pipelines.
Actionable Checklist
- Run Prompt 1 and 2 to establish a factual baseline of the legacy system.
- Use Prompts 3–5 to design service boundaries and target data models.
- Implement Prompts 6–8 to connect data movement and runtime infrastructure.
- Adopt Prompts 9–12 to operationalize delivery and reduce risk during change.
- Prepare Prompts 13–15 for resilience, rollback, and safe cutover.
Measuring Success
- Lead time: Reduction from commit to deploy.
- Change failure rate: Lowered via flags and canaries.
- MTTR: Improved with tracing, metrics, and structured logs.
- Cost efficiency: Right-sized resources and autoscaling.
Continue to refine your prompts as your platform and constraints evolve. Embed the pattern of context, task, acceptance, and validation into your developer culture so that modernization becomes a disciplined, repeatable capability.