The Codex Microservices Playbook: 20 Prompts for Designing, Implementing, and Testing Distributed Systems
The Codex Microservices Playbook: 20 Prompts for Designing, Implementing, and Testing Distributed Systems
DevOps engineers implementing the infrastructure for microservices architectures need specialized prompts for CI/CD pipelines, container orchestration, ande just as important as the application code itself. Our dedicated collection covers 25 ChatGPT-5.5 prompts for DevOps engineers including CI/CD pipelines, infrastructure as code, and incident management.
Introduction
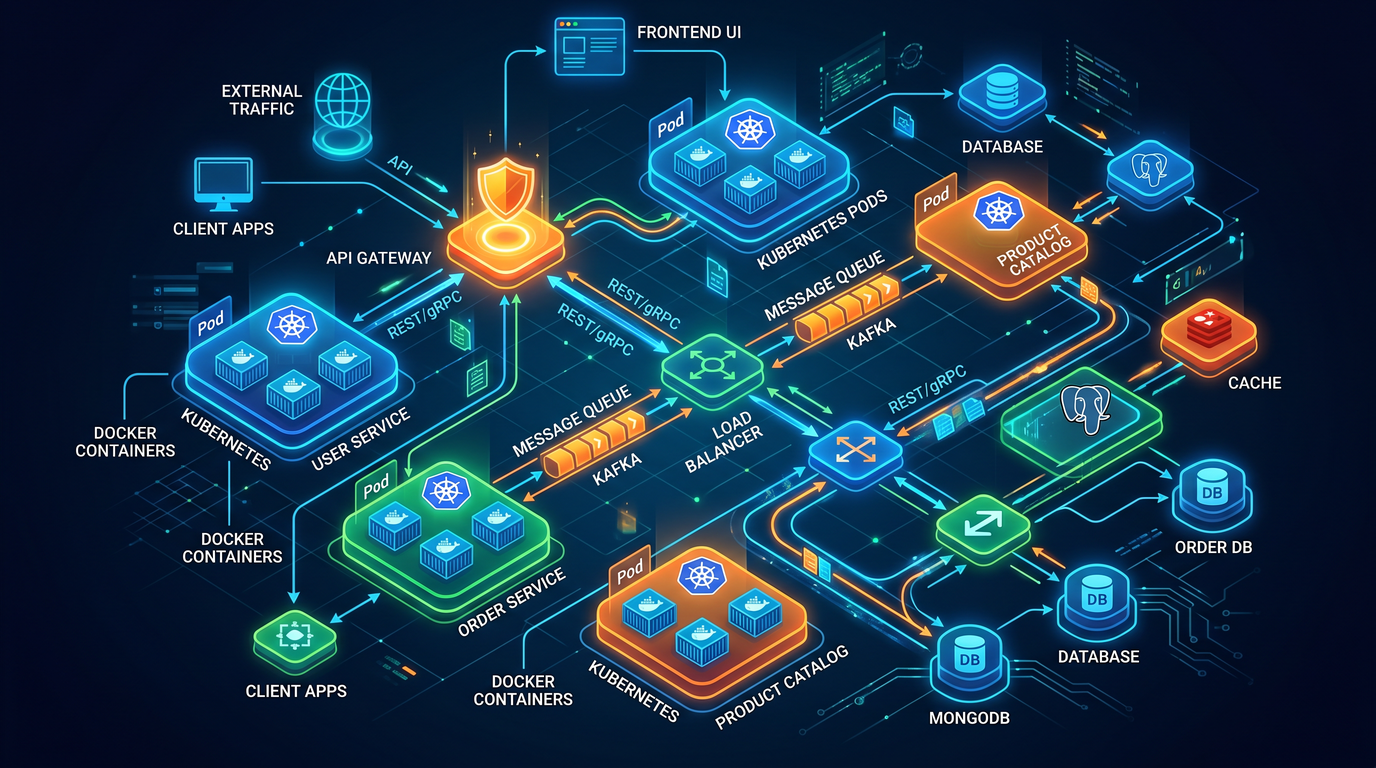
Distributed systems and microservices scale complexity: teams must reason about API boundaries, messaging patterns, operational runbooks, testing strategies, and delivery pipelines. Modern stacks typically include containers (Docker), container orchestration (Kubernetes), RPC frameworks (gRPC), and event streaming (Kafka). This playbook provides 20 production-ready prompts you can paste into an AI assistant to generate architecture diagrams, implementation artifacts, test suites, Kubernetes manifests, CI/CD pipeline scaffolds, and runbook snippets.
Each prompt has a purpose: an explicit instruction, required inputs, constraints, expected outputs, and acceptance criteria. Use them as templates and adapt variable placeholders like {{SERVICE_NAME}}, {{NAMESPACE}}, {{TOPIC_NAME}}, and {{DEPLOYMENT_ENV}}. When interacting with the AI, include your real values and any organizational policies (e.g., compliance/regulatory constraints, internal base images).
Keep the conversation iterative: ask the assistant to explain trade-offs, propose alternatives, and produce automated tests and CI/CD steps. The prompts below are grouped into four practical sections: Architecture Design, Implementation, Testing, and Operations.
Architecture Design (5 Prompts)
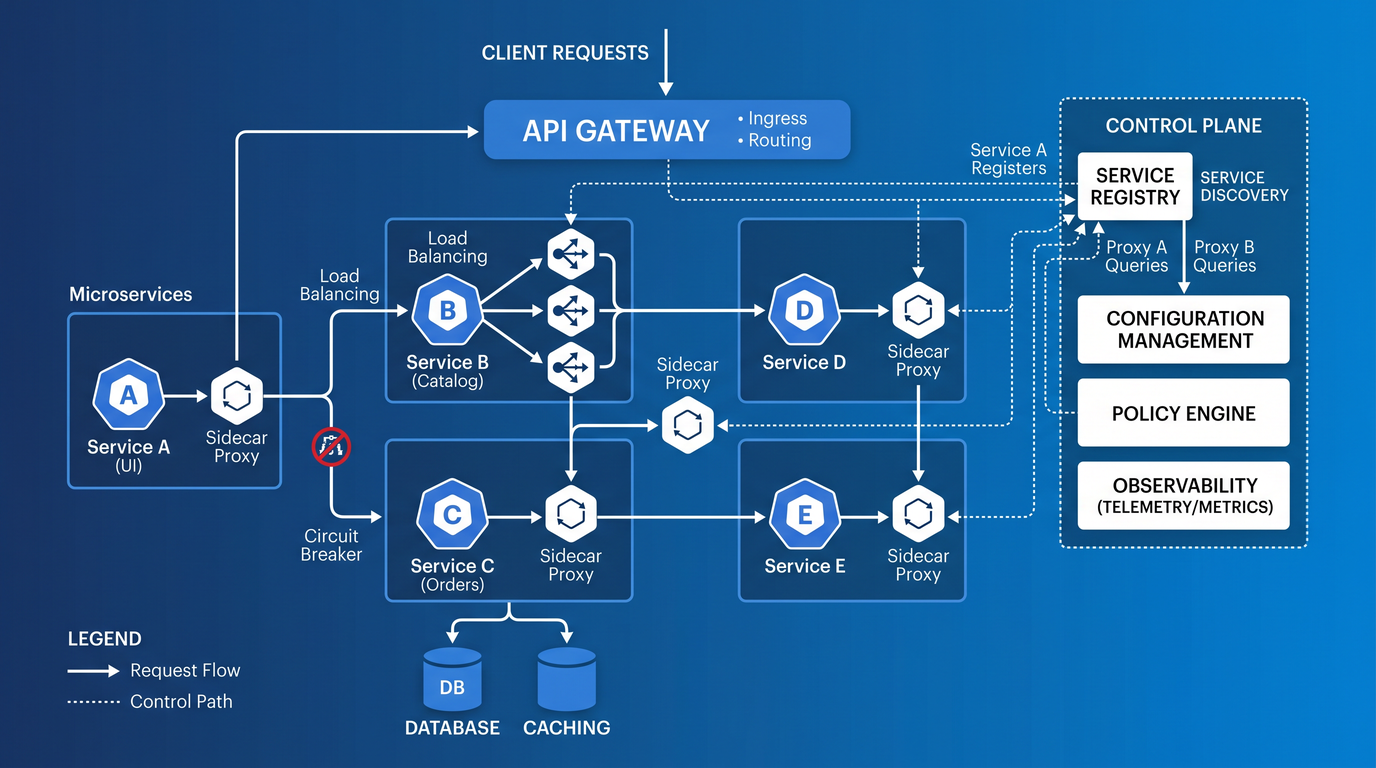
Use these prompts to generate high-level architecture diagrams, service decomposition suggestions, data flow models, and interface contracts. Each prompt helps you capture decisions and produce artifacts that teams can work from.
Prompt 1 — Microservice decomposition and bounded context mapping
Goal: Produce a microservice decomposition for an existing monolith or domain, with bounded contexts, service responsibilities, and suggested gRPC interfaces.
You are an experienced distributed systems architect. Given the domain description and a short list of existing endpoints from a monolith, propose a microservice decomposition aligned to business capabilities and bounded contexts. Output a structured plan in JSON and markdown that includes: list of services with names, responsibilities, data ownership (which datastore per service), suggested gRPC service definitions (method names + request/response fields), Kafka topics for asynchronous events (topic name and event schema), and suggested Kubernetes namespaces. Constraints: prefer single responsibility per service, avoid synchronous calls across more than two services for critical paths, and design for eventual consistency where appropriate.
Inputs:
- domain_description: "{{DOMAIN_DESCRIPTION}}"
- sample_endpoints: ["{{ENDPOINT_1}}", "{{ENDPOINT_2}}", "..."]
- constraints: {max_sync_hops: 2, use_kafka_for_events: true, default_namespace: "{{NAMESPACE}}"}
Expected output: JSON object with:
{
"services": [
{
"name": "orders",
"responsibility": "...",
"data_store": "postgres://...",
"kubernetes_namespace": "...",
"grpc_service": "syntax = \"proto3\"; service Orders { rpc CreateOrder(CreateOrderRequest) returns (CreateOrderResponse); } message CreateOrderRequest { ... }",
"kafka_topics": [{ "name": "orders.events", "schema": { "type":"object", "properties": {...} } }]
}
],
"interaction_patterns": "diagram description",
"tradeoffs": "..."
}
Acceptance criteria: Output lists 4–12 services, includes at least one gRPC service per bounded context, and defines Kafka topic names and simple JSON schemas for each event. Include a short section describing trade-offs and eventual consistency strategies.
Prompt 2 — Data flow diagram and event schema catalog
Goal: Generate a data flow diagram description and a catalog of Kafka event schemas (Avro/JSON Schema) for service interactions, including schema evolution strategy.
Act as a lead data engineer and architect. Based on the provided microservice list and critical user journeys, produce a data flow diagram (text description of nodes and edges suitable for converting to a diagram), and a catalog of Kafka event schemas. For each topic, provide an Avro or JSON Schema, recommended key fields, retention policy recommendations, and compatibility rules (BACKWARD, FORWARD, FULL). Also propose a schema evolution process (who approves, CI checks, rollback plan).
Inputs:
- services: [ "orders", "inventory", "billing", ... ]
- critical_journeys: [ "place_order", "fulfill_order" ]
- kafka_cluster: { brokers: ["kafka-1:9092","kafka-2:9092"], retention_default_hours: 168 }
Expected output:
- text data flow description: "orders -> orders.events -> inventory ..."
- topic catalog: [{"topic": "...","schema": {...},"key": "...","retention_hours": 168,"compatibility":"BACKWARD"}]
- schema_evolution: step-by-step process for changes, CI checks (Avro compatibility test), and governance.
Acceptance criteria: A clear, ordered data flow description with at least 5 topics and compatibility rules. Include example Avro or JSON Schema for each event and practical governance steps.
Prompt 3 — API contract design for gRPC and REST coexistence
Goal: Provide interface design and API gateway strategy to support both gRPC and HTTP/JSON clients, including protobuf design and HTTP transcoding rules.
You are an API design expert. Design gRPC APIs and an HTTP/JSON gateway layer for services that must support both mobile/HTTP clients and internal gRPC services. For each service, provide:
- Protobuf file skeletons (.proto) with package names, messages, and service RPCs.
- HTTP transcoding annotations or mapping (e.g., grpc-gateway or Envoy configuration).
- Versioning strategy for Protobuf services and REST paths.
- Example curl and grpcurl commands to call the same endpoint through both protocols.
Constraints: maintain strong typing for internal calls (gRPC), and friendly JSON for external clients. Use canonical status codes and include metadata headers for tracing and multitenancy.
Inputs:
- services: ["orders","catalog","auth"]
- external_client_requirements: { mobile: true, third_party: true }
- tracing_header: "x-trace-id"
Acceptance criteria: For each service, include a .proto snippet with at least two RPCs, an HTTP mapping example, and two example commands (curl and grpcurl) demonstrating parity between transports.
Prompt 4 — Resilience and fault-domain architecture for Kubernetes
Goal: Produce a resilience strategy that includes pod/disruption budgets, multi-zone partitioning, health checks, resource limits, and circuit-breaker patterns for gRPC calls and Kafka consumers/producers.
You are a reliability engineer designing for production readiness on Kubernetes. Given an application composed of multiple microservices, provide:
- Recommended PodDisruptionBudgets, HorizontalPodAutoscaler rules, and node affinity/anti-affinity to distribute pods across failure domains.
- Liveness/readiness probe suggestions (HTTP/gRPC) for each service.
- Resource (cpu/memory) recommendation templates and limit ranges for namespaces.
- Patterns for gRPC client-side resilience (timeouts, retries, circuit-breakers) and Kafka consumer group handling (pause, retry/backoff topics).
- Example Envoy or Linkerd snippet showing a circuit-breaker configuration for gRPC.
Inputs:
- services: ["orders","inventory","billing"]
- traffic_profile: { p95_rps: 800, burst_capacity: 2000 }
- cloud_provider: "{{CLOUD_PROVIDER}}"
Expected output: YAML snippets for PDB and HPA, JSON describing probes, and example resilience configs.
Acceptance criteria: Include explicit PDB YAML, HPA example, probe examples, and a short explanation of how resilience choices map to SLOs.
Prompt 5 — Security and data governance design
Goal: Create a security plan covering service-to-service mTLS, Kafka ACLs, secrets management in Kubernetes, and data residency requirements.
You are a security architect for cloud-native microservices. Produce a security architecture covering:
- Service-to-service authentication and authorization: mutual TLS (mTLS) details with cert rotation strategy (e.g., cert-manager), RBAC hints for Kubernetes, and network policy examples.
- Kafka access control recommendations: principal naming, ACLs, and producer/consumer patterns to minimize blast radius.
- Secrets management: usage recommendation for Kubernetes secrets vs. external secret manager (HashiCorp Vault, cloud KMS), policies for rotation and least privilege.
- Data protection and residency: encryption-at-rest, encryption-in-transit, and how to annotate services/namespaces containing sensitive data.
Inputs:
- regulatory_constraints: ["GDPR", "SOC2"]
- secrets_system: "{{SECRETS_SYSTEM}}"
- cert_rotation_days: 90
Expected output: Actionable YAML examples (NetworkPolicy, sample Pod annotations for mTLS), Kafka ACL example commands, and compliance checklist.
Acceptance criteria: Concrete examples for mTLS and Kafka ACLs, recommended rotation cadence, and a short compliance checklist mapping to GDPR/SOC2 controls.
Implementation (5 Prompts)
These prompts generate code and configuration: Dockerfiles, Kubernetes manifests, gRPC service implementations, Kafka client patterns, and CI scaffolding. They are targeted to produce production-ready artifacts.
Prompt 6 — Generate a production-ready Dockerfile and multi-stage build
Goal: Produce a secure, small, multi-stage Dockerfile for a service written in Go (or Java/Node/Python if specified), including image labels, non-root user, and healthcheck. Default to Go when language is unspecified.
You are a DevOps engineer generating production Dockerfiles. Given a service language and build constraints, produce a multi-stage Dockerfile optimized for small size, security, and reproducibility. Include:
- Build stage and final stage with minimal base image (scratch or distroless for Go).
- Image labels (org, repo, version).
- Non-root user creation.
- Healthcheck that uses gRPC or HTTP readiness endpoint depending on service.
- Instructions for building with Docker buildx and recommended CI step.
Inputs:
- language: "go"
- service_name: "{{SERVICE_NAME}}"
- port: 8080
- base_builder: "golang:1.20-alpine"
- use_distroless: true
Expected output: A full Dockerfile with comments and an example docker build command.
Acceptance criteria: Dockerfile must contain at least two stages, non-root user, HEALTHCHECK instruction, and build command example. If Go, use go build -ldflags to strip debug symbols and set module proxy caching if appropriate.
Prompt 7 — Scaffold gRPC service with protobufs and server/client stubs
Goal: Produce .proto definitions and idiomatic server and client code in selected language (Go, Java, or Python) with interceptors for tracing and metrics, and instructions for code generation.
You are an engineer scaffolding gRPC services. For service "{{SERVICE_NAME}}", generate:
- A .proto file with package, messages, and 4 RPCs (Create, Get, Update, StreamChanges).
- Instructions for protobuf compilation (protoc commands) targeting Go (replace with language if specified).
- Server skeleton implementing interceptors for OpenTelemetry tracing and Prometheus metrics instrumentation (exposing /metrics).
- Client example showing unary call and streaming consumption.
Inputs:
- language: "go"
- service_name: "{{SERVICE_NAME}}"
- module_path: "github.com/example/{{SERVICE_NAME}}"
- tracing_header: "x-trace-id"
Expected output: .proto content, server.go and client.go skeletons, and a Makefile or script with protoc commands.
Acceptance criteria: Includes valid .proto file (compile with protoc), server and client skeletons, and code generation commands. Instrumentation (tracing + metrics) must be present as code comments or working stubs.
Prompt 8 — Kubernetes manifests and Helm chart scaffold
Goal: Generate production-grade Kubernetes manifests for deployment or a Helm chart scaffold with templates for Deployment, Service, HPA, PDB, ServiceAccount, Role/RoleBinding, and ConfigMap/Secret references.
You are a Kubernetes platform engineer. Generate a Helm chart scaffold (Chart.yaml, values.yaml, templates/) for service "{{SERVICE_NAME}}". Include:
- Deployment with readiness/liveness probes (gRPC probe if supported), resource requests/limits, node affinity, and pod anti-affinity.
- HorizontalPodAutoscaler configured via values.
- PodDisruptionBudget, Service (ClusterIP), and Ingress/ServiceEntry notes (with annotations for external load balancer and TLS).
- ServiceAccount, Role, RoleBinding for the service to restrict cluster permissions.
- ConfigMap example for non-sensitive config and Secret reference template for database credentials.
- Chart best practices: versioning, appVersion field, and recommended values.
Inputs:
- namespace: "{{NAMESPACE}}"
- image_repo: "registry.example.com/{{SERVICE_NAME}}"
- replicas: 3
Expected output: Files content for Chart.yaml, values.yaml, and key templates with comments.
Acceptance criteria: Provide complete chart files for core templates and example values that render into Deployment and Service. Include notes for Helm values that control HPA thresholds and PDB minAvailable.
Prompt 9 — Kafka client patterns and consumer/producer templates
Goal: Provide reliable Kafka producer and consumer code patterns in your chosen language, covering at-least-once delivery, idempotence, retry semantics, and backpressure management (e.g., backoff topics or poison queue).
You are a streaming systems engineer. Deliver production-ready Kafka client code for both producer and consumer in language "{{LANGUAGE}}". The templates should include:
- Producer with idempotent writes (enable.idempotence=true or equivalent), retry/backoff settings, and acks=all.
- Consumer group example with commit semantics (manual or auto) and handling of transient errors with exponential backoff.
- Error handling pattern: move-to-dead-letter-topic or write metadata to a retry topic with exponential backoff.
- Suggestions for message key choice, partitioning strategy, and schema registry usage.
- Example config for TLS/SASL if cluster is secured.
Inputs:
- topic: "{{TOPIC_NAME}}"
- consumer_group: "{{SERVICE_NAME}}-consumer-group"
- schema_registry_url: "{{SCHEMA_REGISTRY}}"
Expected output: Producer.java/producer.go/producer.py and consumer code, plus configuration examples for production.
Acceptance criteria: Include explicit producer/consumer configuration lines for idempotence and acks, and demonstrate moving failing messages to a dead-letter or retry topic with metadata for debugging.
Prompt 10 — CI pipeline job for build, test, image, and push
Goal: Generate a CI pipeline job configuration (GitHub Actions, GitLab CI, or Jenkinsfile) that builds the service, runs unit tests, generates artifacts, runs static analysis, builds container images, pushes to registry, and triggers Helm release to staging.
You are a CI/CD engineer. Create a CI job for GitHub Actions (or change to GitLab or Jenkins upon request) that:
- Checks out code, sets up the language toolchain, runs linters and unit tests.
- Builds a reproducible artifact (binary or wheel/jar), runs security scanning (SCA) against dependencies, and runs a static analysis tool.
- Uses Docker buildx to build multi-arch images, tags images with commit SHA and semantic version (if present), and pushes to registry with credentials from secrets store.
- Uses Helm to render templates and deploy to a "staging" namespace via a service account token.
- Provides short rollback instructions and an artifact retention policy.
Inputs:
- ci_system: "github"
- image_repo: "registry.example.com/{{SERVICE_NAME}}"
- deploy_namespace: "staging"
- secrets_store: "{{CI_SECRETS_STORE}}"
Expected output: .github/workflows/ci.yml content with steps and environment variables, and instructions for necessary repository secrets.
Acceptance criteria: The workflow must include cache steps, build and push images with appropriate tags, test steps, and a helm upgrade/install staging step using a service account secret. Include a security-scan step (Snyk/Trivy) example.
Testing (5 Prompts)
Testing distributed systems requires multiple layers: unit tests, contract tests, integration tests with Kafka and gRPC, chaos testing for resilience, and end-to-end smoke tests. These prompts help produce test suites, mocks, and test data generation.
Prompt 11 — Unit and integration test scaffolding for gRPC services
Goal: Generate unit test templates and integration test harness for a gRPC service using testcontainers (or local Kubernetes test env), including mocked dependencies and an in-memory Kafka or test Kafka cluster.
You are a test engineer. Produce:
- Unit test examples for service handlers using table-driven tests (language-specific), mocking database and downstream gRPC clients.
- Integration test harness that spins up a Kafka broker and the service (using Testcontainers or a k3s in-memory cluster), sends test events, calls gRPC endpoints, and asserts expected states in the service's datastore.
- Instructions for running tests in CI with parallelism limits and reporting.
Inputs:
- language: "go"
- test_framework: "go test"
- mock_library: "mockery" or "gomock"
Expected output: test files with test cases (Create, Update, error path), docker-compose or testcontainers snippet to run Kafka, and test run commands.
Acceptance criteria: Include at least 6 unit tests and an integration test that demonstrates producing to a topic and asserting that the service updates state and emits expected events.
Prompt 12 — Contract testing for gRPC and Kafka topics
Goal: Generate consumer-driven contract tests for gRPC clients and Kafka producers using Pact or similar frameworks. Include schema validation against schema registry.
You are an engineer implementing contract tests. For each upstream/downstream pair:
- Create a contract that describes the expectations (request/response for gRPC; message schema and metadata for Kafka).
- Provide a Pact-style test for the consumer that validates the producer behavior.
- Include automation to run schema compatibility checks against Schema Registry on CI and fail on incompatible changes.
- Provide fixtures and example test data.
Inputs:
- contracts: [ {"consumer":"billing","provider":"orders"},{"consumer":"inventory","provider":"orders"} ]
- schema_registry: "{{SCHEMA_REGISTRY_URL}}"
Expected output: Pact JSON or contract DSL for each contract, test code showing verification, and CI snippet to register/verify schemas.
Acceptance criteria: For each contract, produce a consumer-side test plus a provider verification guideline. Include a script or CI step that registers the schema and validates compatibility in the registry.
Prompt 13 — Chaos and fault injection test plan
Goal: Create a controlled chaos engineering plan that exercises network partitions, pod failures, Kafka broker unavailability, and delayed gRPC responses, with measurable SLOs and rollback steps.
You are an SRE designing chaos tests. Produce a test plan that includes:
- Goals and scope: which services and environments (staging).
- Experiments: e.g., kill 30% of service pods, introduce 500ms latency between orders and inventory, bring down one Kafka broker, corrupt a message schema.
- Success criteria mapped to SLOs: error budget thresholds, latency thresholds, and recovery time objectives.
- Safety guards: abort conditions, automated rollback, and runbook steps for manual intervention.
- Tooling examples: kubectl, chaos-mesh, litmuschaos, and traffic control (tc) commands.
Inputs:
- slos: { p99_latency_ms: 500, error_rate_percent: 1, rto_seconds: 300 }
- environment: "staging"
Expected output: A sequence of experiments with commands, expected outcomes, and measurement metrics to assert.
Acceptance criteria: At least 5 experiments with explicit commands, metrics to record, and abort conditions. Include sample Grafana query snippets to verify outcomes.
Prompt 14 — End-to-end smoke test and Canary validation
Goal: Generate an end-to-end smoke test script that simulates a critical user journey (place_order -> inventory reserve -> billing charge) and a canary validation checklist for automated deployment verification.
You are a QA automation engineer. Produce:
- A smoke test script that uses HTTP/gRPC and Kafka to execute a full user journey across services, verifying side effects in databases and emitted events.
- Assertions for each step and automatic cleanup.
- A canary validation checklist with automated checks (health probes, telemetry checks, business metrics adequacy) and manual checks.
- Example automation that runs as a post-deploy job in CI/CD and blocks promotion on failed checks.
Inputs:
- user_journey: ["place_order","reserve_inventory","charge"]
- services_endpoints: { orders: "orders.svc.cluster.local:8080", inventory: "...", billing: "..." }
Expected output: Bash/Node/Python script for the smoke test and a canary checklist in YAML suitable for CI gating.
Acceptance criteria: The script must be executable with provided endpoints and include metric checks (e.g., no increase in 5xx errors) and event assertions on Kafka topics.
Prompt 15 — Load test scenarios and tooling integration (k6/Locust/JMeter)
Goal: Design load testing scenarios that simulate realistic traffic patterns for microservices and include Kafka producer/consumer load, as well as gRPC client load testing. Provide k6 scripts or Locust tasks with warmup, ramp-up, sustained, and spike phases.
You are a performance engineer. Provide:
- Load test scenarios (warmup, ramp-up, steady-state, spike, cooldown) with RPS or VUs for each phase.
- A k6 or Locust script that issues gRPC calls (using a gRPC client extension for k6 or Locust) and produces messages to Kafka at controlled rates.
- Metrics to capture (latency percentiles, error rate, consumer lag, producer throughput).
- Guidance for running in CI or ephemeral clusters, resource sizing recommendations for test cluster.
Inputs:
- target_rps: 2000
- p95_target_ms: 200
- services_to_test: ["orders","inventory"]
Expected output: k6 script or Locustfile, and a step-by-step runbook for running tests against staging clusters.
Acceptance criteria: Include a script with at least three phases and explicit checks for target latencies and error rates. Provide sample analysis commands to compute percentiles and consumer lag.
Operations (5 Prompts)
Operational prompts help generate runbooks, alerting rules, incident playbooks, and deployment automation. They focus on observability, incident response, safe rollouts, and day-two operations such as schema migrations and backup strategies.
Prompt 16 — Observability stack configuration and alerting rules
Goal: Generate Prometheus alert rules, Grafana dashboard templates, and tracing/span conventions for gRPC and Kafka interactions. Include SLI/SLO definitions and alert thresholds.
You are a monitoring engineer. Produce:
- Prometheus alert rules (YAML) for high error rate, high latency, consumer lag on Kafka topics, and Kafka broker health.
- Suggested Grafana dashboard panels (JSON model or description) for service latency, request rate, error rate, and Kafka topic lag.
- Tracing conventions: standard span names for gRPC server and client, attributes to include (service, operation, topic, partition, offset), and correlation between Kafka events and request traces.
- SLI/SLO definitions and example alerts mapping to SLO burn rate.
Inputs:
- slos: { availability: 99.95, latency_p95_ms: 300 }
- prometheus_namespace: "monitoring"
Expected output: YAML for alerts, dashboard panel descriptions, and tracing conventions.
Acceptance criteria: Provide at least 6 alert rules with severity levels and runbook links, a dashboard layout description for at least two services, and tracing attribute lists to include consistently.
Prompt 17 — Incident response playbook and postmortem template
Goal: Create a step-by-step incident playbook for common failure modes (e.g., Kafka outage, increased error rates, gRPC dependency failure), including roles, commands, mitigations, and a postmortem template with RCA guidance.
You are an SRE writing incident response documentation. For each incident type (Kafka broker down, high consumer lag, gRPC dependency timeout, degraded cluster nodes) provide:
- Incident triggers (alert thresholds).
- Immediate mitigation steps (e.g., scale consumers, pause partitions, failover brokers).
- Diagnostic commands (kubectl, kafka-topics.sh, kafka-consumer-groups.sh, logs, describe).
- Communication templates for status page and stakeholder updates.
- Postmortem template that includes timeline, impact, root cause, corrective actions, and follow-ups.
Inputs:
- oncall_team: "{{ONCALL_TEAM}}"
- pager_rota: "{{PAGER_ROTA}}"
Expected output: Playbook steps with commands and a postmortem markdown template.
Acceptance criteria: Include concrete commands for diagnosing Kafka and Kubernetes, a clear escalation path, and a postmortem template with suggested fields and severity classification.
Prompt 18 — Schema migration and data migration runbook
Goal: Provide a safe schema migration plan for protobuf and Kafka schemas, and a database migration strategy that minimizes downtime and supports rollbacks.
You are a data migration lead. Produce a stepwise plan for:
- Protobuf schema changes and schema registry migrations (backwards/forwards compatibility approach).
- Rolling out changes across services that produce or consume modified topics.
- Database migrations using a safe pattern (e.g., expand/contract or toggle flags) and a backfill procedure for historical data.
- Tools and commands for migrating (kafka-rest, kafka-console-producer/consumer, db migration tool).
- Rollback guidance and observation checks to verify correctness.
Inputs:
- change_description: "{{SCHEMA_OR_DB_CHANGE}}"
- services_affected: ["orders","billing"]
- downtime_allowed_seconds: 0
Expected output: A migration checklist with steps, commands, and verification queries.
Acceptance criteria: Provide a zero-downtime migration approach (if downtime_allowed_seconds=0), list of compatibility checks (schema registry commands), and a rollback plan with exact commands to reverse changes if necessary.
Prompt 19 — Safe rollout strategy and automatic canary promotion
Goal: Create a deployment strategy that supports canary releases, automated promotions based on telemetry, and safe rollback triggers. Integrate with Kubernetes, Istio/Envoy, and CI outputs.
You are a release engineer. Design a safe rollout with:
- Traffic shifting plan using Istio/Envoy or Kubernetes native (Service mesh) to route X% traffic to canary.
- Automated promotion rules: metrics (latency, error rate, successful business events) thresholds and monitoring time window.
- Rollback triggers and automated rollback action (helm rollback or traffic shift).
- CI integration: post-deploy job runs smoke tests and Canary metrics check returns pass/fail to promote.
- Example manifests (VirtualService/DestinationRule) and a simple controller script to drive promotions.
Inputs:
- canary_traffic_steps: [10,30,100]
- evaluation_window_minutes: 15
- critical_metric: "p99_latency_ms"
Expected output: YAML examples, a controller skeleton (bash/python) for traffic promotion, and CI job definition to gate promotion.
Acceptance criteria: Include concrete traffic shifting YAML, promotion logic with metric checks, and auto-rollback conditions. Provide commands to run the promotion script and a sample CI job to call it.
Prompt 20 — Backup, restore, and disaster recovery plan
Goal: Draft a DR plan covering persistent storage, Kafka topic snapshots, and schema & config backups for Kubernetes clusters. Include RPO/RTO planning and a runbook to restore to a new region or cluster.
You are a disaster recovery planner. Create a DR plan that includes:
- Backup strategy for databases (logical/full/incremental), volumes (Velero snapshots), and Kafka (MirrorMaker or kafka-replicator).
- Kafka topic backup and restore procedures (export/consume/publish), including offsets and consumer group handling.
- Kubernetes cluster config and secrets backup approach (etcd snapshots, secrets export) and secure storage of keys.
- Recovery plan to restore services in a new region: order of operations, prechecks, and validation steps.
- RTO/RPO guidance and periodic DR test cadence.
Inputs:
- rpo_hours: 1
- rto_hours: 4
- regions: ["us-east-1","us-west-2"]
Expected output: Actionable DR checklist, commands for backup/restore, and a test schedule.
Acceptance criteria: Include a step-by-step restore plan with commands and expected verification queries. The plan must meet inputs for RTO and RPO or explain trade-offs if impossible.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
How to Use These Prompts Effectively
The prompts are written to be explicit and production-ready. To get the best results:
- Replace placeholders like
{{SERVICE_NAME}},{{NAMESPACE}},{{TOPIC_NAME}}, and{{SCHEMA_REGISTRY}}with your environment values. - When the prompt returns code artifacts (Dockerfile, .proto, YAML), run local validations immediately: protoc, kubeval, docker build –no-cache, and unit tests.
- Iterate: ask follow-up prompts for alternatives (e.g., swap gRPC for REST, use Kafka vs. change data capture) and to justify trade-offs.
- Use the generated artifacts as a scaffold. Always review security-related snippets (credentials, TLS configs) and align with your organization’s security policies.
Suggested Workflow
- Start with Architecture Design prompts to define services, topics, and interfaces.
- Use Implementation prompts to scaffold code, Dockerfiles, and Helm charts.
- Run Testing prompts to build local integration harnesses and CI test steps.
- Use Operations prompts to configure observability, alerts, DR, and canary promotion logic.
- Continuously improve by adding contract tests and automation for schema governance and migration safety.
The prompts are intentionally prescriifacts. When integrating generated assets into production, adty scans as mandatory gates.