Codex Rate Limit Banking and Flexible Resets: The Complete Guide to Optimizing Your Development Throughput
Codex Rate Limit Banking and Flexible Resets: The Complete Guide to Optimizing Your Development Throughput
By ChatGPT AI Hub Editorial Team — June 18, 2026
For enterprise development teams who have integrated OpenAI Codex into their daily workflows, rate limits have historically been a source of frustration. The traditional model was rigid: you received a fixed number of requests per time window, and unused capacity simply evaporated at reset time. Whether your team was in a sprint freeze or grinding through a critical deployment, your rate limit budget treated every hour the same way. That paradigm has fundamentally changed.
OpenAI’s introduction of rate limit banking and flexible resets for Codex represents one of the most developer-friendly policy changes in the platform’s history. Instead of watching unused capacity disappear when the clock resets, teams can now accumulate that capacity and deploy it strategically during high-intensity development sessions. The implications for development throughput optimization are substantial — and most teams are only beginning to understand how to take full advantage of the system.
This guide covers everything you need to know: the mechanics of how banking works under the hood, proven strategies for maximizing throughput during heavy coding sprints, team-level allocation approaches that work for organizations of every size, and how the referral program integrates with your banking balance. Whether you’re a solo developer or managing Codex access for a hundred-person engineering organization, the strategies here will transform how you plan and execute your most demanding technical work.
Rate limit banking works alongside broader credit management strategies to maximize development throughput. For a complete overview of enterprise cost controls including usage dashboards, team allocation, and budget alerts, see our detailed guide on Codex credit management and rate limit optimization which covers the full administrative toolkit available to enterprise teams.
Understanding the Fundamentals of Codex Rate Limit Banking
Before diving into optimization strategies, it’s critical to understand precisely how rate limit banking works at a mechanical level. Misconceptions about the system are common, and building your throughput strategy on a flawed mental model will produce disappointing results.
The Core Banking Mechanism
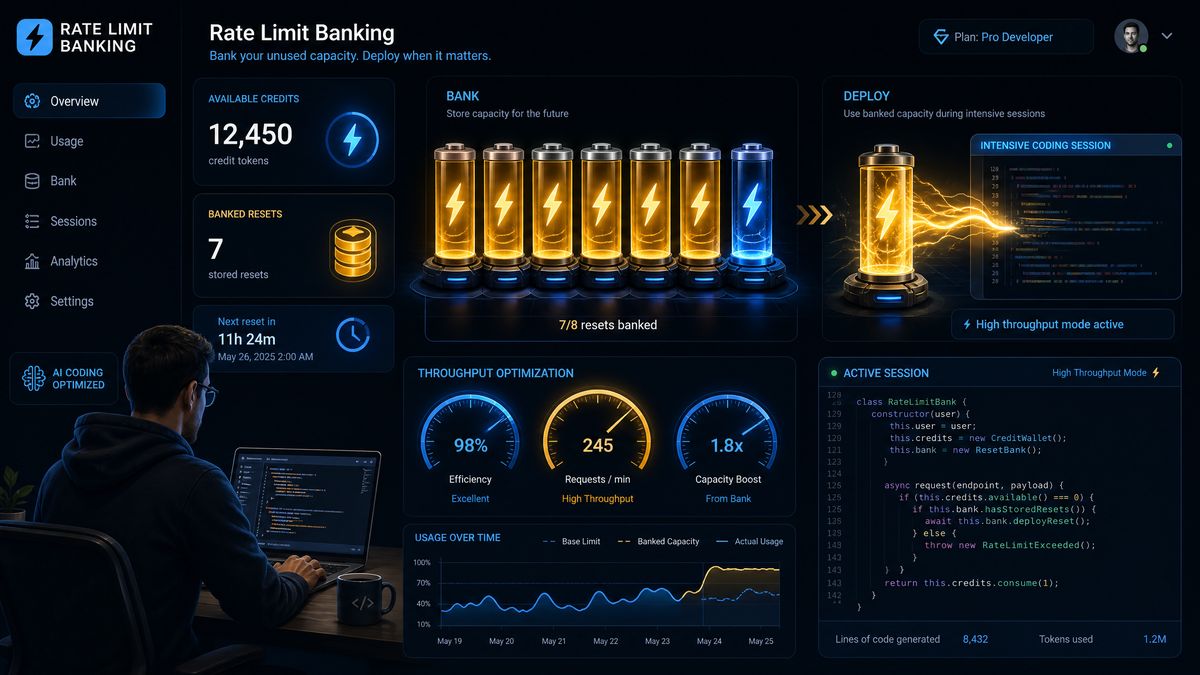
Under the traditional rate limit model, Codex enforced a rolling window of requests per minute (RPM) and tokens per minute (TPM). When the window elapsed, any unused capacity was discarded, and you started fresh. Banking changes this by introducing a reservoir model: unused capacity within a billing period is converted into banked credits that persist for a defined rollover window.
The key parameters of the banking system are:
- Base Rate Allocation: Your plan’s standard RPM and TPM limits, which remain unchanged as your guaranteed floor capacity.
- Banking Accumulation Rate: The fraction of unused capacity that converts to banked credits at each reset interval. This is not a 1:1 conversion — typically 70-80% of unused capacity banks, with a small systemic reserve maintained for infrastructure stability.
- Maximum Bank Balance: A ceiling on how many credits can accumulate in your reserve. This prevents indefinite accumulation and is typically set at 5-10x your base rate allocation depending on your subscription tier.
- Bank Decay Window: Banked credits are not permanent. They expire on a rolling basis, typically 30 days from the date they were earned. Credits are consumed on a FIFO (first in, first out) basis.
- Burst Deployment: When you exceed your base rate allocation, the system draws automatically from your bank balance to fulfill requests. This happens transparently — your application code doesn’t change.
Token Banking vs. Request Banking
A critical nuance that many developers miss: the banking system tracks both token-level and request-level credits independently. These two reserves accumulate and deplete separately, which means you can be token-rich and request-poor (or vice versa) depending on your usage patterns.
This distinction matters enormously for strategy. If your workload involves many small, targeted completions — autocomplete suggestions, inline documentation generation, single-function refactors — you’ll burn through request credits faster relative to tokens. Conversely, if you regularly submit large context windows with extensive system prompts for complex architectural reasoning tasks, you’ll deplete tokens faster while barely touching your request ceiling.
Understanding your own usage profile is the first prerequisite for effective banking strategy. OpenAI’s usage dashboard now provides a granular breakdown of your historical token-to-request ratio, and reviewing this data before designing your banking approach is non-negotiable for serious optimization work.
Flexible Resets Explained
Flexible resets are the companion feature to banking that gives you control over when your base rate allocation refreshes. In the legacy system, resets occurred on a fixed schedule — typically every minute for RPM limits and once per day for daily TPM caps. Flexible resets allow you to manually trigger a rate limit refresh within certain constraints, at the cost of consuming banked credits to “purchase” the early reset.
The exchange rate for a manual reset scales with how much time remains in your natural reset window. Triggering a reset 30 seconds before it would occur naturally costs essentially nothing. Triggering it immediately after a natural reset — essentially halving your reset interval — costs significantly more banked credits. The cost function is non-linear, designed to encourage strategic rather than reflexive reset usage.
// Pseudocode illustrating reset cost calculation
function calculateResetCost(timeElapsedSinceLastReset, totalResetWindowSeconds) {
const fractionRemaining = 1 - (timeElapsedSinceLastReset / totalResetWindowSeconds);
// Cost is proportional to the fraction of the window you're skipping
// with a quadratic penalty for very early resets
const baseCost = fractionRemaining * baseResetCreditCost;
const earlyResetMultiplier = fractionRemaining > 0.5 ? Math.pow(fractionRemaining, 1.5) : fractionRemaining;
return baseCost * earlyResetMultiplier;
}
// Example: 10 seconds into a 60-second window
const cost = calculateResetCost(10, 60);
// fractionRemaining = 0.833 — this is an expensive early reset
// Better to wait and use the natural reset
The practical takeaway: flexible resets are most valuable when you’re a few seconds away from a natural reset but have a latency-sensitive request queue backing up. Using them aggressively mid-window is generally a poor use of banked credits unless you’re in a genuine sprint scenario where throughput is the only variable that matters.
Banked rate limits become especially valuable when running parallel development workflows that consume multiple task slots simultaneously. Our architecture guide on building multi-agent parallel workflows in Codex Desktop explains how to structure concurrent agent tasks that benefit from saved capacity during intensive development sprints.
Mapping Your Development Patterns to Banking Strategy
Effective rate limit banking is not a universal prescription — it’s a customization exercise that requires honest accounting of your team’s development cadence. The teams that extract the most value from banking are those that have taken time to characterize their usage patterns with precision.
Identifying Your Peak Usage Windows
Pull your last 90 days of Codex API usage data and plot it by hour of day and day of week. Most development teams have highly predictable usage profiles with clear peaks and troughs. Common patterns include:
- Sprint-end surges: Usage spikes dramatically in the 48-72 hours before sprint review as developers rush to complete feature work. During these windows, teams may consume 3-5x their average hourly rate limit allocation.
- Morning quiet periods: Many teams have low Codex utilization in the first 1-2 hours of the workday while engineers work through meetings, planning, and context-setting. This is prime banking accumulation time.
- CI/CD pipeline peaks: If your team uses Codex for automated code review, documentation generation, or test creation in your CI pipeline, you’ll see predictable usage spikes triggered by merge activity — often concentrated around mid-morning and mid-afternoon.
- Cross-timezone dead zones: Teams operating across multiple time zones often have 4-8 hour windows where no engineers are actively working, creating significant banking accumulation opportunities.
Calculating Your Effective Banking Yield
To calculate how much burst capacity you can realistically build up, you need to model your banking yield. Here’s a practical framework:
# Python script to estimate banking accumulation
import datetime
# Your plan's base allocation (example values)
BASE_RPM = 500
BASE_TPM = 100000
BANKING_EFFICIENCY = 0.75 # 75% of unused capacity banks
MAX_BANK_MULTIPLIER = 7 # Max bank = 7x base allocation
BANK_DECAY_DAYS = 30
# Historical usage data (average fraction of base allocation used per hour)
# Index 0 = midnight, index 23 = 11pm
hourly_usage_fraction = [
0.05, 0.03, 0.02, 0.01, 0.01, 0.02, # Midnight-5am
0.10, 0.25, 0.60, 0.75, 0.85, 0.90, # 6am-11am
0.80, 0.85, 0.90, 0.88, 0.70, 0.50, # Noon-5pm
0.30, 0.20, 0.15, 0.10, 0.08, 0.06 # 6pm-11pm
]
def calculate_daily_banking():
banked_today = 0
for hour, fraction in enumerate(hourly_usage_fraction):
unused_fraction = max(0, 1 - fraction)
banked_fraction = unused_fraction * BANKING_EFFICIENCY
banked_rpm = BASE_RPM * banked_fraction
banked_tpm = BASE_TPM * banked_fraction
banked_today += banked_tpm # Track in tokens for simplicity
return banked_today
daily_bank = calculate_daily_banking()
max_bank = BASE_TPM * 60 * 24 * MAX_BANK_MULTIPLIER # Theoretical max
print(f"Estimated daily banking accumulation: {daily_bank:,.0f} tokens")
print(f"Days to reach max bank balance: {max_bank/daily_bank:.1f} days")
print(f"Effective burst multiplier after 1 week: {min(daily_bank * 7, max_bank) / (BASE_TPM * 60):.1f}x per minute")
Running this kind of analysis against your actual usage data gives you a realistic picture of how much burst capacity you can realistically bank before a planned intensive development session. Most teams are surprised to discover they’re accumulating significantly more than they assumed.
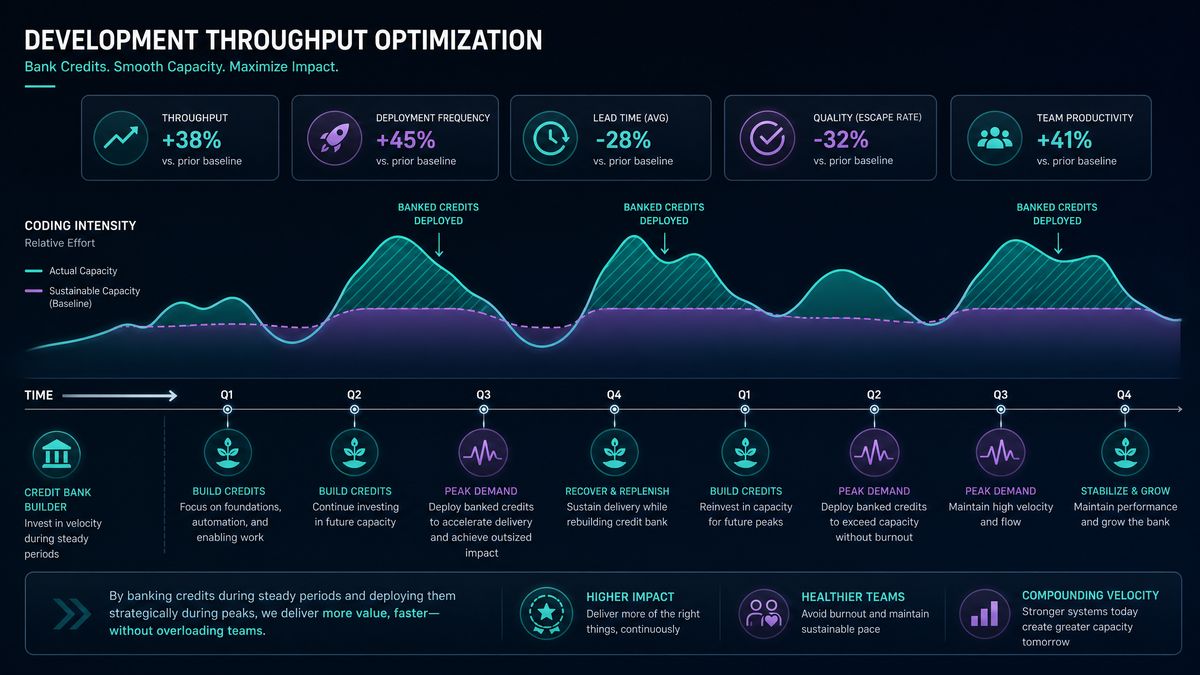
Advanced Strategies for Sprint and Release Cycle Optimization
With a clear picture of your banking mechanics and usage patterns, you can now design proactive strategies for your most demanding development scenarios. The following approaches have been validated across enterprise teams of varying sizes and technical domains.
The Pre-Sprint Banking Protocol
The most impactful change most teams can make is implementing a deliberate pre-sprint banking protocol. The concept is straightforward: in the 3-5 days before a sprint begins, consciously reduce non-critical Codex usage to allow your bank balance to accumulate to maximum capacity before the sprint’s heavy lifting begins.
In practice, this means:
- Audit and defer non-critical automation: Identify any scheduled or automated Codex tasks (documentation refreshes, style linting, boilerplate generation) and reschedule them to fire after the sprint’s peak intensity period.
- Communicate conservation windows to the team: Set expectations that the 48 hours before sprint kickoff are a “Codex conservation” period. Engineers should batch their exploratory and low-priority completion work rather than peppering the API with individual requests.
- Monitor bank balance approach to cap: Use the OpenAI API’s balance endpoint to track your accumulation. When you’re at 90%+ of max bank, there’s no benefit to continued conservation — encourage normal usage.
- Schedule the sprint’s heaviest AI-assisted work for days 2-4: Day 1 of a sprint typically involves planning overhead. Targeting peak Codex usage for days 2-4 gives you one additional day of accumulation post-kickoff.
Burst Mode Configuration for Peak Sessions
When you’re ready to deploy your banked capacity, configuring your Codex integration for maximum throughput requires more than simply firing off more requests. You need to structure your request patterns to take full advantage of burst capacity without triggering secondary rate limit mechanisms.
import openai
import asyncio
import time
from collections import deque
class RateLimitAwareCodexClient:
def __init__(self, api_key, base_rpm=500, burst_multiplier=5):
self.client = openai.AsyncOpenAI(api_key=api_key)
self.base_rpm = base_rpm
self.burst_multiplier = burst_multiplier
self.effective_rpm = base_rpm * burst_multiplier # When bank is full
self.request_timestamps = deque()
async def smart_completion(self, prompt, model="codex-enterprise-v2", **kwargs):
"""
Rate-limit-aware completion that respects burst capacity.
Uses a sliding window to avoid exceeding effective RPM even during burst.
"""
await self._wait_for_capacity()
try:
response = await self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
**kwargs
)
self._record_request()
return response
except openai.RateLimitError as e:
# Bank is exhausted — back off to base rate
print(f"Rate limit hit — bank likely exhausted. Falling back to base rate.")
await asyncio.sleep(60 / self.base_rpm)
return await self.smart_completion(prompt, model, **kwargs)
async def _wait_for_capacity(self):
"""Implements sliding window rate limit enforcement."""
now = time.time()
window_start = now - 60 # 60-second window
# Remove timestamps outside the window
while self.request_timestamps and self.request_timestamps[0] < window_start:
self.request_timestamps.popleft()
# If at effective RPM limit, wait
if len(self.request_timestamps) >= self.effective_rpm:
oldest_in_window = self.request_timestamps[0]
sleep_time = oldest_in_window + 60 - now + 0.01 # Small buffer
if sleep_time > 0:
await asyncio.sleep(sleep_time)
def _record_request(self):
self.request_timestamps.append(time.time())
# Usage example for batch processing during burst mode
async def process_codebase_batch(file_paths, client):
tasks = []
for filepath in file_paths:
with open(filepath, 'r') as f:
code = f.read()
prompt = f"Review this code for security vulnerabilities and performance issues:\n\n{code}"
tasks.append(client.smart_completion(prompt, max_tokens=1024))
results = await asyncio.gather(*tasks, return_exceptions=True)
return results
Token Efficiency Maximization During High-Throughput Sessions
During burst sessions when you’re drawing down bank balance, token efficiency becomes doubly important. Every wasted token is not just a cost issue — it’s reducing your burst window duration. Implementing aggressive prompt optimization for high-throughput sessions can extend your effective burst capacity by 20-40%.
Key token efficiency techniques for burst sessions:
- Context compression: Rather than submitting full file context for localized changes, use a sliding window that includes only the immediately relevant code plus a compressed summary of the broader file structure.
- Response length constraints: Set explicit max_tokens limits matched to your actual need. If you’re generating a 10-line function, capping at 200 tokens is appropriate — don’t leave the default at 4096.
- Instruction deduplication: In batch scenarios where many requests share common instructions (style guides, project conventions, language preferences), use the system prompt field efficiently and keep per-request prompts minimal.
- Streaming for latency-sensitive tasks: Streaming responses allows your application to begin processing output before the completion finishes, effectively increasing your subjective throughput even without changing your token consumption rate.
Team-Level Allocation Strategies for Enterprise Organizations
For organizations managing Codex access across multiple teams, the banking system introduces a new dimension of resource planning: how do you allocate banked capacity fairly and strategically across competing engineering priorities?
Centralized vs. Distributed Banking Models
Enterprise Codex accounts have the option to manage rate limits at the organization level (centralized) or to distribute allocations to individual teams via sub-keys with their own rate limit envelopes (distributed). Each model has distinct implications for banking.
| Dimension | Centralized Banking | Distributed Banking |
|---|---|---|
| Bank balance visibility | Single unified view, easier to monitor | Per-team visibility, harder to aggregate |
| Burst capacity allocation | Can redirect full org bank to any priority | Teams bank independently, no reallocation |
| Fairness between teams | Requires active governance, prone to monopolization | Each team owns their capacity, naturally fair |
| Emergency surge handling | Excellent — redirect all reserves to critical path | Limited to individual team’s banked balance |
| Administrative overhead | Lower initial setup, higher ongoing governance | Higher initial setup, lower ongoing governance |
| Waste minimization | Low — idle teams’ capacity benefits active teams | Higher — idle teams’ banked credits may expire unused |
| Recommended for | Orgs with variable team workloads, shared infrastructure | Orgs with consistent team workloads, strong autonomy culture |
Implementing a Rate Limit Governance Framework
For organizations choosing centralized banking, establishing clear governance protocols prevents the most common failure mode: high-priority teams burning through shared bank reserves, leaving nothing for others during simultaneous peak periods.
A practical governance framework includes the following components:
- Priority tier classification: Assign each team or workload type to a priority tier (Critical, High, Standard, Background). Critical workloads (production incident support, security patches) have preemptive access to banked reserves. Background workloads (automated documentation updates, non-urgent code quality scans) are the first to be throttled when bank balance drops below a defined threshold.
- Bank balance thresholds: Define action triggers at specific bank balance levels. For example: above 70% capacity — unrestricted usage; 40-70% — Background workloads throttled to base rate; 20-40% — Standard workloads throttled; below 20% — all non-Critical workloads reduced to 50% of base allocation.
- Sprint coordination calendar: Require teams to register planned high-intensity development windows at least 5 days in advance. This allows other teams to proactively reduce usage during overlapping periods, preventing simultaneous bank drawdowns.
- Bank balance reporting: Weekly automated reports to engineering leadership showing each team’s contribution to banking (through low usage periods) and drawdowns (through burst usage). This creates visibility and natural accountability.
# Example: Rate limit governance enforcement via API middleware
import os
from enum import Enum
import redis
class WorkloadPriority(Enum):
CRITICAL = 1
HIGH = 2
STANDARD = 3
BACKGROUND = 4
class CentralizedBankingGovernor:
def __init__(self, redis_client, org_max_bank_tokens):
self.redis = redis_client
self.org_max_bank = org_max_bank_tokens
# Throttle thresholds (fraction of max bank)
self.thresholds = {
'unrestricted': 0.70,
'throttle_background': 0.40,
'throttle_standard': 0.20,
'emergency': 0.10
}
def get_allowed_rate_multiplier(self, priority: WorkloadPriority) -> float:
"""Returns the fraction of base rate this workload is allowed at current bank level."""
bank_fraction = self._get_current_bank_fraction()
if bank_fraction >= self.thresholds['unrestricted']:
return 5.0 # Full burst access for all tiers
elif bank_fraction >= self.thresholds['throttle_background']:
multipliers = {
WorkloadPriority.CRITICAL: 5.0,
WorkloadPriority.HIGH: 4.0,
WorkloadPriority.STANDARD: 3.0,
WorkloadPriority.BACKGROUND: 1.0 # Throttled to base rate
}
return multipliers[priority]
elif bank_fraction >= self.thresholds['throttle_standard']:
multipliers = {
WorkloadPriority.CRITICAL: 5.0,
WorkloadPriority.HIGH: 3.0,
WorkloadPriority.STANDARD: 1.0, # Throttled to base rate
WorkloadPriority.BACKGROUND: 0.5 # Below base rate
}
return multipliers[priority]
else: # Emergency mode
multipliers = {
WorkloadPriority.CRITICAL: 3.0,
WorkloadPriority.HIGH: 1.0,
WorkloadPriority.STANDARD: 0.5,
WorkloadPriority.BACKGROUND: 0.25
}
return multipliers[priority]
def _get_current_bank_fraction(self) -> float:
current_balance = float(self.redis.get('org:bank:current_tokens') or 0)
return current_balance / self.org_max_bank
This kind of middleware-layer governance ensures that your most critical development work always has access to burst capacity, while still allowing all teams to benefit from the banking system under normal conditions.
Cross-Team Banking Coordination Patterns
Beyond governance frameworks, high-performing engineering organizations develop cultural practices around rate limit coordination that amplify the technical mechanisms. The teams that consistently achieve the best development throughput during intensive periods are not just technically sophisticated — they’ve developed operational habits that treat rate limit capacity as a shared organizational resource.
Three coordination patterns that consistently deliver results:
- The Staggered Sprint Pattern: When multiple teams are operating on similar sprint cadences, deliberately offset their most Codex-intensive sprint phases by 3-5 days. If Team A is doing their heavy implementation work in sprint days 5-8, Team B’s intensive phase falls in days 2-5. This prevents simultaneous bank drawdowns and allows each team to benefit from the other’s conservation period.
- The Dedicated Automation Window: Shift all non-interactive, automated Codex workloads (CI pipeline, scheduled analysis jobs, documentation generation) to run during the lowest-usage window in your organization’s 24-hour cycle. For most global teams, this is a 3-4 hour window between midnight and 4am UTC. This accumulates bank balance during periods when no developers are working, effectively getting “free” burst capacity from time that would otherwise contribute zero banking value.
- The Release Day Protocol: Treat release days as special events requiring advance rate limit preparation. At least 48 hours before a major release, flag the upcoming high-intensity window in your coordination system. Teams not directly involved in the release shift to conservation mode, explicitly building up the organization’s bank balance in preparation for what is typically the highest single-day Codex usage of any sprint.
Referral Program Integration: Multiplying Your Banking Capacity
OpenAI’s referral program for Codex enterprise accounts offers a mechanism that many organizations have been slow to leverage: referral credits that directly augment your rate limit bank balance. Understanding how these credits work and designing a systematic approach to accumulating them can materially increase your burst capacity without any additional spend.
How Referral Credits Interact with Banking
Referral credits earned through the Codex enterprise referral program are deposited directly into your organization’s bank balance, subject to the same maximum bank cap as organically earned credits. This means they’re immediately deployable as burst capacity and decay on the same 30-day rolling window as your accumulated credits.
The credit structure typically follows a tiered model:
| Referral Type | Credit Amount | Vesting Schedule | Expiry Window |
|---|---|---|---|
| Individual developer referral (Pro plan) | 5% of referee’s first 3 months spend | Monthly as referee is billed | 30 days from vesting |
| Team plan referral (10+ seats) | 8% of referee’s first 3 months spend | Monthly as referee is billed | 45 days from vesting |
| Enterprise referral (50+ seats) | 12% of referee’s first year spend | Quarterly | 90 days from vesting |
| Partnership referral (API integration vendor) | Custom negotiated | Custom schedule | Custom — typically 180 days |
Building a Systematic Referral Strategy
For enterprise development organizations, the most effective referral approaches leverage your existing vendor and partner relationships rather than cold outreach. Consider the following high-yield referral scenarios:
- Technology vendor introductions: If your organization regularly evaluates and procures developer tooling, introducing vendors who are potential Codex API consumers (consulting firms, software agencies, tooling vendors) converts existing relationship capital into banking credits.
- Internal subsidiary or division referrals: Large enterprises with multiple business units or subsidiaries that operate independent IT budgets can generate referral credits by facilitating Codex adoption across their own corporate family — with appropriate disclosure to OpenAI per their terms of service.
- Developer community presence: Engineering teams that are active in open source communities, technical conferences, or developer advocacy naturally create referral opportunities through authentic product recommendations. Structuring these conversations to include referral links is straightforward and doesn’t compromise authenticity.
- SI and consulting partner coordination: If your organization works with systems integrators or consulting partners who implement your infrastructure, these relationships are strong referral candidates — they often need Codex access for client work anyway and benefit from a warm introduction to enterprise programs.
Credit Timing Optimization for Banking
Because referral credits vest on the referee’s billing schedule, you can strategically time your referral activities to ensure credits vest in alignment with your planned high-intensity development periods. If you know a major product launch is planned for month 4 of the year, prioritizing referral conversations in months 1-2 ensures that referral credits from those relationships vest and are available in your bank during your peak need window.
Track your referral pipeline with projected vesting dates as part of your overall rate limit capacity planning. A simple spreadsheet mapping referral status to expected credit vest dates, cross-referenced against your engineering calendar, gives you a surprisingly clear picture of your anticipated burst capacity weeks or months in advance.
Monitoring, Alerting, and Observability for Banking-Aware Applications
Once your banking strategy is operational, maintaining visibility into your bank balance and usage patterns is essential for catching problems early and continuing to refine your approach. Building proper observability into your Codex integration is not optional at scale — it’s the difference between proactively managing your capacity and reactively scrambling when a sprint hits an unexpected rate limit wall.
Essential Metrics to Track
A comprehensive observability setup for Codex rate limit banking should capture the following metrics at minimum:
- Current bank balance (RPM and TPM separately): Polled at 5-minute intervals during active development periods, 30-minute intervals otherwise.
- Bank balance trend: Rolling 24-hour delta — is your bank filling or draining? This is more actionable than a point-in-time balance reading.
- Request success rate: The fraction of API calls that succeed without rate limit errors. A declining success rate before you’ve intentionally entered burst mode is an early warning sign of unexpected usage spikes.
- Burst utilization rate: What fraction of your effective burst capacity (base + bank) is currently being consumed? This normalizes for plan tier differences and gives a meaningful utilization figure.
- Credit expiry forecast: How many banked credits will expire in the next 7 and 30 days if current usage patterns continue? This drives “use it or lose it” decisions about low-priority automation work that could consume credits before they decay.
# Prometheus metrics integration for Codex banking observability
from prometheus_client import Gauge, Counter, Histogram
import openai
import asyncio
# Define metrics
bank_balance_tokens = Gauge(
'codex_bank_balance_tokens',
'Current token bank balance',
['balance_type'] # 'current', 'max', 'expiring_7d', 'expiring_30d'
)
bank_balance_requests = Gauge(
'codex_bank_balance_requests',
'Current request bank balance',
['balance_type']
)
api_requests_total = Counter(
'codex_api_requests_total',
'Total Codex API requests',
['status', 'model', 'workload_priority']
)
api_latency_seconds = Histogram(
'codex_api_latency_seconds',
'Codex API request latency',
['model'],
buckets=[0.1, 0.25, 0.5, 1.0, 2.5, 5.0, 10.0, 30.0]
)
burst_utilization = Gauge(
'codex_burst_utilization_ratio',
'Current utilization as fraction of effective burst capacity'
)
async def update_banking_metrics(org_client):
"""Fetch current banking status from OpenAI API and update Prometheus metrics."""
try:
status = await org_client.get_rate_limit_status()
bank_balance_tokens.labels(balance_type='current').set(
status.token_bank.current_balance
)
bank_balance_tokens.labels(balance_type='max').set(
status.token_bank.max_balance
)
bank_balance_tokens.labels(balance_type='expiring_7d').set(
status.token_bank.expiring_in_7_days
)
# Calculate burst utilization
effective_capacity = status.base_rpm + status.token_bank.current_balance
current_usage = status.current_rpm
utilization = current_usage / effective_capacity if effective_capacity > 0 else 0
burst_utilization.set(utilization)
except Exception as e:
print(f"Failed to fetch banking metrics: {e}")
# Alert thresholds for PagerDuty/OpsGenie integration
ALERT_THRESHOLDS = {
'bank_critical_low': 0.10, # Alert when bank < 10% of max
'expiry_waste_warning': 0.25, # Alert when >25% of bank expires unused in 7d
'burst_saturation': 0.90, # Alert when burst utilization > 90%
'bank_accumulation_failure': 0 # Alert when bank hasn't grown in 48 hours (flat)
}
Building Dashboards for Banking Capacity Planning
Raw metrics are most useful when visualized in a planning-oriented dashboard. The goal isn’t just to know your current bank balance — it’s to have enough context to make decisions about upcoming development work weeks in advance.
A well-designed banking capacity dashboard includes four core views: a real-time panel showing current balance against max capacity with color-coded status indicators; a 30-day historical chart overlaying bank balance trends against sprint calendar markers; a forward-looking forecast model showing projected balance at future dates based on recent accumulation/drawdown rates; and a team consumption breakdown for centralized banking setups, showing which teams are the heaviest consumers and contributors.
Sharing this dashboard broadly across engineering leadership creates shared awareness of rate limit capacity as a planning input — analogous to how teams track compute budget or sprint velocity. This cultural shift is often as impactful as any technical optimization.
Common Mistakes and How to Avoid Them
Even experienced engineering teams make predictable mistakes when implementing rate limit banking strategies. Understanding these failure modes in advance saves significant frustration.
Mistake 1: Treating Banking as Unlimited Burst Insurance
Banking is a capacity smoothing mechanism, not an unlimited burst buffer. The maximum bank balance cap means there’s a hard ceiling on how much burst capacity you can accumulate, and that ceiling is relatively modest compared to truly unrestricted access. Teams that discover banking and immediately schedule enormous batch processing jobs without checking their balance first inevitably hit walls they didn’t anticipate.
Always calculate your expected drawdown before starting a burst session and confirm it’s within your available balance. This takes less than 5 minutes and prevents the scenario where a high-priority automation job stalls halfway through a critical overnight processing run.
Mistake 2: Ignoring Credit Expiry
The 30-day rolling expiry on banked credits means that teams with highly variable usage patterns — say, organizations with a significant holiday shutdown or a quieter summer period — can accumulate substantial bank balances that expire before being used. The waste isn’t catastrophic (you didn’t pay for unused banked credits directly), but it represents a missed opportunity.
Schedule a monthly review of your expiry forecast metrics. If more than 15% of your current bank balance is projected to expire unused in the next 7 days, deliberately schedule lower-priority work that you’d otherwise be deferring — documentation generation, comprehensive test suite creation, codebase analysis — to consume those credits productively before they decay.
Mistake 3: Optimizing for RPM Without Considering TPM
The dual-track nature of Codex rate limits (requests and tokens tracked separately) means optimizing one dimension while ignoring the other produces asymmetric results. Teams that focus exclusively on reducing their request count while submitting increasingly large prompts often find themselves unexpectedly token-constrained during burst sessions, even though their request bank shows substantial reserves.
Always monitor both dimensions. If your token bank is consistently depleting faster than your request bank, it’s a signal to implement more aggressive context compression. The inverse pattern — request bank depleting while token bank stays full — suggests batching multiple related tasks into single requests where the task structure allows it.
Mistake 4: Failing to Account for Model-Specific Rate Limits
Different Codex model variants often carry distinct rate limit envelopes. If your organization uses multiple model tiers — perhaps a lighter model for autocomplete and a more capable model for complex refactoring tasks — each model tracks its own bank balance independently. A strategy optimized for your primary model provides no benefit to your secondary model’s banking situation.
Extend your banking strategy and monitoring to cover each model variant in your usage stack separately. This is a common oversight that becomes apparent only when the secondary model starts hitting limits during exactly the burst sessions the primary model was optimized for.
Future Directions: What’s Coming to Codex Rate Limit Management
OpenAI’s engineering team has signaled several upcoming enhancements to the rate limit banking system that enterprise development teams should be aware of as they build their strategies. While exact release timelines are subject to change, these capabilities are on the roadmap and will significantly expand the sophistication of banking-based throughput optimization.
Scheduled Rate Limit Reservations
An upcoming feature will allow organizations to reserve a portion of their banked capacity for specific future time windows — essentially a calendar-based reservation system for burst capacity. This eliminates the risk of one team inadvertently draining shared bank reserves hours before another team’s critical scheduled workload runs. For organizations managing Codex across complex engineering calendars, this will be a major operational improvement.
Cross-Organization Credit Transfers
For enterprise groups managing multiple OpenAI accounts (common in large companies with separate legal entities or acquired businesses), the ability to transfer banked credits between organizational accounts within a corporate group is being piloted. This creates the equivalent of a corporate treasury function for rate limit capacity — centralizing reserves with the ability to deploy them strategically to any subsidiary account facing a usage surge.
Dynamic Banking Tiers Based on Historical Usage
OpenAI is also exploring a model where an organization’s maximum bank multiplier scales dynamically with their demonstrated usage history and payment reliability. Organizations with consistent, high-volume usage patterns and clean payment histories would qualify for higher bank caps — up to 10-15x base allocation — compared to the standard 5-7x available to newer accounts. This creates a long-term incentive for organizations to invest in the kind of consistent, thoughtful usage patterns that naturally optimize for banking accumulation.
Putting It All Together: A 30-Day Banking Optimization Plan
For teams starting from scratch with rate limit banking optimization, the following 30-day implementation plan provides a structured path from initial assessment to a fully operational banking strategy.
- Days 1-3 (Baseline Assessment): Pull historical usage data, calculate your average token-to-request ratio, identify peak and trough usage windows, and document your sprint and release calendar for the next quarter.
- Days 4-7 (Infrastructure Setup): Implement banking observability metrics (balance, trend, expiry forecast, burst utilization), configure alerting thresholds, and set up your banking capacity dashboard.
- Days 8-14 (Governance Design): For centralized banking setups, design and document your priority tier framework and bank balance threshold actions. Communicate the new governance model to engineering teams with sufficient lead time for behavioral adaptation.
- Days 15-21 (First Managed Conservation Period): Select a 5-day window before a planned intensive development period and execute your first deliberate pre-sprint banking protocol. Track accumulation against your model predictions to validate your yield assumptions.
- Days 22-28 (Controlled Burst Deployment): Execute your first planned burst session using banked reserves. Monitor bank drawdown rate against your pre-session projections and note any discrepancies for model calibration.
- Days 29-30 (Review and Calibrate): Compare actual banking yield and burst drawdown against your models. Adjust accumulation efficiency parameters and usage fractions based on observed data. Publish findings to your engineering leadership to build shared understanding.
By the end of this 30-day cycle, your organization will have a fully operational banking strategy grounded in real data rather than theoretical estimates — and a foundation for continuously refining your approach as your usage patterns evolve.
Conclusion
Codex rate limit banking and flexible resets represent a genuine paradigm shift in how development teams can plan and execute intensive AI-assisted coding work. The transition from rigid, use-it-or-lose-it rate limits to a banking model that rewards efficient usage with deployable burst capacity aligns OpenAI’s infrastructure incentives with developers’ actual working patterns in a way that the previous system never did.
The teams that will extract the most value from this system are not necessarily those with the highest base rate allocations — they’re the ones that invest in understanding the mechanics, characterizing their usage patterns with precision, implementing proper observability, and developing organizational practices that treat rate limit capacity as a managed shared resource rather than an anonymous infrastructure constraint.
The complete banking optimization stack — pre-sprint conservation protocols, burst mode configuration, centralized governance frameworks, referral program integration, and forward-looking capacity planning — requires real investment to implement properly. But the return on that investment is measured in hours of uninterrupted peak-throughput development capacity exactly when your team needs it most: during the critical final days of a sprint, the final push before a major release, or the intensive debugging sessions that determine whether a production incident resolves in hours or days.
Start with the 30-day implementation plan, ground your strategy in your actual historical data, and invest in the observability infrastructure to know what’s working. The development throughput gains you’ll achieve are not marginal — for teams that implement these strategies fully, the difference between pre- and post-optimization performance during peak development windows is transformative.
Article by ChatGPT AI Hub Editorial Team | June 18, 2026 | Category: Guide | Coverage: OpenAI Codex, Rate Limit Optimization, Enterprise Development Strategy
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.