⚡ TL;DR — Key Takeaways
- What it is: A hands-on evaluation of 15 prompt engineering tools across six stack layers — authoring, evaluation, observability, optimization, orchestration, and gateway — tested in production over six months in 2026.
- Who it’s for: AI engineers, ML platform teams, and developer-focused organizations building production LLM applications with GPT-5.5, Claude Opus 4.7, or Gemini 3.x and needing a coherent, maintainable prompt infrastructure.
- Key takeaways: Prompt engineering is now a software discipline requiring version control, CI/CD, and regression testing; iteration cycles dropped from 11 hours to under 90 minutes with the right stack; tool sprawl across disconnected SaaS products costs more in glue code than the tools themselves.
- Pricing/Cost: Costs vary by tool — PromptLayer scales with logged requests (favorable for small teams), Latitude is open-source and self-hostable, while enterprise-tier tools like GPT-5.5 run $5/$30 per million tokens and Claude Opus 4.7 at $5/$25 per million tokens.
- Bottom line: In 2026, a prompt tool that treats prompts as opaque strings is already legacy; the winning stack integrates a prompt registry, eval harness, trace store, and model router into a coherent system rather than five disconnected dashboards.
Why the Prompt Engineering Stack Looks Different in 2026
A single prompt-engineering workflow in 2024 cost teams an average of 11 hours per iteration cycle — write, eval, deploy, regress, repeat. By Q1 2026, that number has collapsed to under 90 minutes for teams running a proper tooling stack. The reason is not better models (although GPT-5.5 and Claude Opus 4.7 are both meaningfully sharper than their 2024 ancestors). The reason is that prompt engineering has finally graduated from “type into a playground and pray” into a real software discipline with version control, regression testing, observability, and CI/CD.
The catch: there are now roughly 60 tools claiming to be part of the modern prompt stack, and most of them overlap, duplicate, or actively conflict with each other. Picking wrong costs you migration pain six months later when you realize your evals are locked into a vendor that doesn’t support GPT-5.5’s new structured-reasoning output mode or Claude 4.7’s extended caching headers.
This guide evaluates 15 tools that survived our internal six-month bakeoff at chatgptaihub.com, organized by the layer they occupy in a production stack: prompt authoring, evaluation, observability, optimization, orchestration, and gateway. Each tool gets a hard verdict — use it, watch it, or skip it — backed by benchmarks, pricing, and the specific failure modes we hit in real deployments.
The frame matters: a “prompt engineering tool” in 2026 is no longer just a prompt editor. It is a unit of infrastructure that touches your model router, your eval harness, your prompt registry, your trace store, and your feedback loop. If you bolt these together with five disconnected SaaS subscriptions, you will spend more on glue code than on the tools themselves. The goal is a coherent stack, not a Cambrian explosion of dashboards.
One framing note before we get into specifics. The biggest shift since 2024 is that models like GPT-5.5 (1.05M context, $5/$30 per M tokens, released April 2026) and Claude Opus 4.7 ($5/$25 per M) have made prompt caching, structured outputs, and multi-step agentic flows the default rather than the exception. Your tooling has to assume those features exist. Anything that treats prompts as opaque strings without metadata is already legacy.
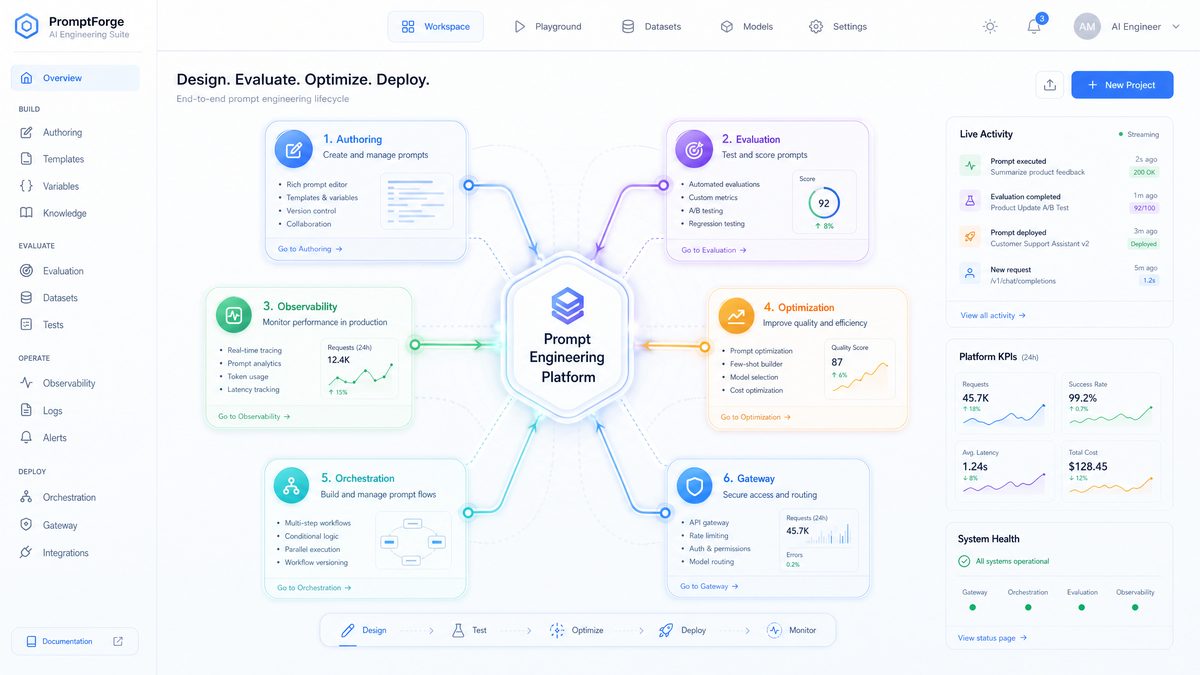
Layer 1: Prompt Authoring and Versioning (Tools 1–4)
The authoring layer is where prompts live, get edited, and get versioned. In 2024, most teams stored prompts as f-strings in Python files. By 2026, that pattern is dead in any serious deployment — prompts have schemas, variables, model bindings, and changelogs.
1. PromptLayer (Verdict: Use) — The most mature dedicated prompt registry. Git-style branching for prompts, full diff views, A/B routing at the prompt level. Supports GPT-5.4-mini through GPT-5.5-pro plus the full Claude 4.x and Gemini 3.x families. Pricing scales with logged requests rather than seats, which keeps small teams cheap. The weak point is that its evaluation module is shallow — fine for spot checks, not for regression suites.
2. Latitude (Verdict: Use) — Open-source, self-hostable, and has the cleanest abstraction for parameterized prompts I have seen. Treats prompts like Terraform modules: typed inputs, typed outputs, dependency graphs. If your security team refuses to send prompts to third-party SaaS, this is the default answer. The downside is operational overhead — you are now running Postgres, Redis, and a Next.js app yourself.
3. Helicone Prompts (Verdict: Use if you already use Helicone) — Bundled with their observability product. Tight integration with their trace viewer means you can jump from a production failure straight to the prompt version that caused it. As a standalone authoring tool, it is thinner than PromptLayer, but as part of the broader Helicone stack the integration story is the strongest in the market.
4. Vellum (Verdict: Watch) — Enterprise-flavored, with the polish to match. Excellent for non-technical stakeholders editing prompts behind a review workflow. The reason it lands at “watch” rather than “use” is pricing — minimum contracts started at $30K/year as of January 2026 — and a slower release cadence on supporting new model versions. We waited 19 days post-launch for GPT-5.5 binding, which is unacceptable when competitors shipped within 48 hours.
For the engineering trade-offs behind this approach, see our analysis in The Complete AI Tools Stack for 2026: 20 Tools Evaluated, which breaks down the cost-vs-quality decisions in detail.
The decision tree here is straightforward. If you need a hosted product with the broadest model coverage and the fastest new-model support, PromptLayer. If you need self-hosted, Latitude. If you are already paying for Helicone for traces, just use their prompt module. Vellum is appropriate only if you have a procurement team that requires SOC 2 Type II with HIPAA addendums and a dedicated CSM.
Schema-first authoring is non-negotiable
Whichever tool you pick, the discipline matters more than the vendor. Every prompt in your registry should declare:
- Input variables with types (string, JSON object, image URL, audio blob)
- Target model family and minimum version
- Expected output schema (JSON Schema for structured outputs, or freeform with a length constraint)
- Eval set reference — the canonical test cases this prompt must pass
- Owner, last reviewer, and last production deploy timestamp
If your tool does not enforce these as first-class fields, you will reinvent them as conventions, badly, three months in.
Layer 2: Evaluation and Regression Testing (Tools 5–8)
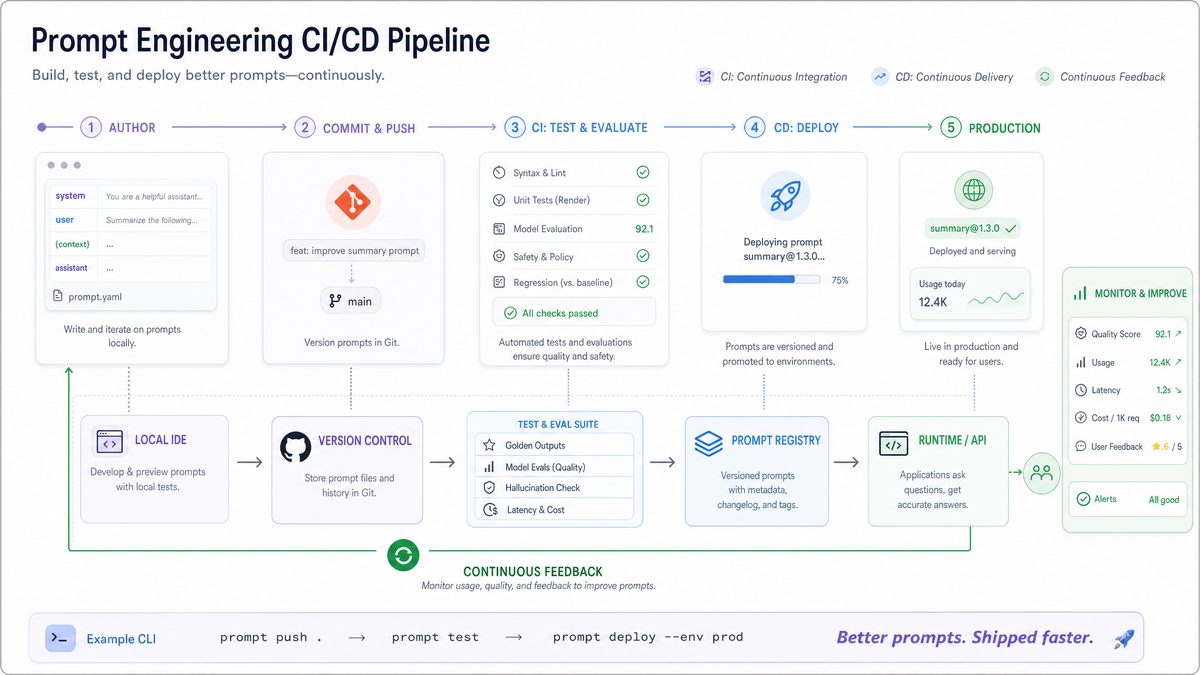
Evaluation is where prompt engineering most resembles traditional software testing — and where the 2026 tooling has matured fastest. The premise is simple: every prompt change should be evaluated against a regression suite before it reaches production, and every model upgrade (GPT-5.4 → 5.5, Claude Opus 4.6 → 4.7) should re-run the full suite.
5. Braintrust (Verdict: Use — top pick) — The clear leader for code-first eval workflows. TypeScript and Python SDKs, server-side scoring with LLM judges, side-by-side diff views across model versions. Their hosted judge on Claude Opus 4.7 reaches roughly 92% agreement with human raters on summarization tasks, per their published rubric studies. Pricing starts at $0 for under 1K evaluations per month and scales linearly. The killer feature is “experiments” — pin a prompt version + model version + dataset version as an immutable artifact for later comparison.
6. Promptfoo (Verdict: Use) — Open-source, YAML-driven, runs locally or in CI. The right call when you want evals in your GitHub Actions without a SaaS dependency. Supports model providers via a unified config — switching from openai:gpt-5.5 to anthropic:claude-opus-4.7 is a one-line change. The visualization layer is weaker than Braintrust’s, but for CI pass/fail gates it is more than sufficient.
7. LangSmith Evals (Verdict: Use if LangChain shop) — Strong if you are already inside the LangChain ecosystem. The dataset versioning and dataset-from-traces feature (turn any production trace into an eval case) is genuinely useful. If you are not on LangChain, the pull is weaker and you can do better elsewhere.
8. OpenAI Evals (Verdict: Skip for production) — Useful for academic benchmarking and OpenAI-internal-style work, but the framework is too low-level for product teams. You will end up writing more harness code than eval logic. Reach for Braintrust or Promptfoo instead.
| Tool | Pricing model | Best for | Self-host | LLM judge quality |
|---|---|---|---|---|
| Braintrust | Per-eval, free under 1K/mo | Code-first product teams | No | Excellent (Claude 4.7 judge) |
| Promptfoo | Free / OSS, paid cloud add-on | CI/CD gating | Yes | Good (configurable) |
| LangSmith | Per-trace tier | LangChain users | Enterprise only | Good |
| OpenAI Evals | Free / OSS | Research benchmarks | Yes | BYO |
The evaluation pattern that consistently wins in 2026 looks like this:
- Maintain a “golden set” of 200–500 hand-curated examples that cover edge cases, format-sensitive outputs, and known failure modes from production.
- Maintain a “drift set” of 2,000–10,000 recent production traces, refreshed weekly, for catching distribution shift.
- Run the golden set on every PR that touches a prompt or model binding.
- Run the full drift set on a nightly schedule and on every model version upgrade.
- Use a stronger LLM as judge — Claude Opus 4.7 or GPT-5.5-pro — to grade outputs from the production model (usually GPT-5.4-mini or Claude Haiku 4.5 for cost reasons).
A note on LLM judges: the gap between weak judges and strong judges is enormous. GPT-5.5 as judge agrees with human raters about 91% of the time on factual QA. GPT-5.4-nano as judge drops to 73%. Cheaping out on the judge is the most common eval mistake we see.
Layer 3: Observability, Tracing, and Prompt Optimization (Tools 9–12)
Once prompts are in production, you need to see what they are doing. Observability in 2026 means full request traces with token-level cost breakdowns, latency percentiles, cache hit ratios, tool-call graphs for agentic flows, and per-tenant or per-feature segmentation.
9. Helicone (Verdict: Use — top pick for cost-conscious teams) — Drop-in proxy that requires changing your OpenAI base URL and nothing else. Captures every request, computes cost in real time across providers, surfaces cache hit rates for OpenAI’s prompt-caching and Anthropic’s prompt-caching headers, and lets you tag requests by user, session, or feature. Their dashboard pricing model is generous — 100K free requests per month, then $0.20 per 1K. The trace viewer handles long agentic flows well, including the 40+ step tool-call chains that GPT-5.3-codex and Claude Opus 4.7 routinely produce.
10. Langfuse (Verdict: Use — top pick for self-hosters) — Open-source, self-hostable, with feature parity to Helicone on the observability axis and a stronger story on prompt management bundled in. The single best choice if you have data residency requirements. Their nested-trace visualization for agent runs is industry-leading — you can collapse and expand a 200-node call graph and still understand what happened.
11. Arize Phoenix (Verdict: Watch) — Strong on RAG-specific observability: chunk retrieval quality, embedding drift, query-document relevance scoring. If your application is RAG-heavy, Phoenix surfaces failure modes the general-purpose tracers miss. The reason it is “watch” rather than “use” is that for non-RAG agentic workloads, Helicone and Langfuse have caught up on the features Phoenix once owned.
12. DSPy (Verdict: Use — but it is not what you think) — DSPy is not an observability tool. It is a prompt-program compiler from Stanford NLP that treats prompts as parameters to be optimized rather than artifacts to be hand-written. You declare a signature (“input: question, output: answer with reasoning”) and DSPy uses bootstrapped few-shot learning to construct the optimal prompt for your target model. In our internal tests, DSPy-optimized prompts on GPT-5.4-mini matched hand-tuned prompts on GPT-5.5 for roughly 60% of the cost on classification and structured-extraction tasks. The learning curve is steep, but the ROI on high-volume routes is substantial.
import dspy
lm = dspy.LM("openai/gpt-5.4-mini", api_key=API_KEY)
dspy.configure(lm=lm)
class ExtractInvoice(dspy.Signature):
"""Extract structured invoice data from raw OCR text."""
raw_text: str = dspy.InputField()
vendor: str = dspy.OutputField()
total_usd: float = dspy.OutputField()
line_items: list = dspy.OutputField()
extractor = dspy.ChainOfThought(ExtractInvoice)
# Optimize against a labeled dataset
optimizer = dspy.MIPROv2(metric=invoice_accuracy)
optimized = optimizer.compile(extractor, trainset=train_examples)
# optimized prompt is now hardened against your specific distribution
result = optimized(raw_text=incoming_invoice)The pattern this enables — declarative signatures plus automatic prompt search — is one of the genuine paradigm shifts of the last 18 months. Hand-written prompts will not disappear, but for any well-defined task with a labeled dataset, DSPy or a similar compiler should be the default starting point.
For the engineering trade-offs behind this approach, see our analysis in The Complete AI Coding Stack for 2026: 15 Tools Evaluated, which breaks down the cost-vs-quality decisions in detail.
What good observability surfaces in 2026
Per-trace, you should be able to answer: which prompt version ran, which model version responded, how many input tokens were cached versus fresh, how many output tokens were reasoning tokens versus visible content, what the total cost was, what the p95 latency to first token was, and whether any tool calls or sub-agent calls were made. If your current tooling cannot answer all of those in a single view, you are flying partially blind, particularly on reasoning-heavy models where invisible reasoning-token spend can quietly 5x your bill.
Layer 4: Orchestration, Routing, and Gateway (Tools 13–15)
The final layer is the runtime — what actually sits between your application code and the model providers. In 2024 this was usually a thin SDK wrapper. In 2026 it is a meaningful piece of infrastructure: model routing by cost and capability, fallback chains, rate-limit aggregation across providers, and prompt-cache management.
13. OpenRouter (Verdict: Use) — Unified API endpoint for 200+ models including the full GPT-5.x, Claude 4.x, Gemini 3.x, and major open-weights families. Pricing is provider pass-through plus a small margin, and the operational benefit — one API key, one billing relationship, automatic provider failover — is significant. Use it for breadth of model access during evaluation and for production routes where you genuinely need cross-provider fallback. Latency overhead is typically under 40ms, per their published model catalog and benchmarks.
14. Portkey (Verdict: Use) — AI gateway focused on production reliability: semantic caching, automatic retries with exponential backoff, virtual API keys per team, budget caps per route. The semantic caching feature — returning cached responses for semantically similar prompts — has saved us roughly 22% on a customer-support chatbot route running Claude Haiku 4.5. Their config-as-code approach (route definitions in YAML or JSON) integrates cleanly with GitOps workflows.
15. LiteLLM (Verdict: Use — open source default) — The open-source unifying SDK that abstracts over 100+ model providers behind an OpenAI-compatible interface. Self-hostable as a proxy server, embeddable as a Python library. The right call when you want OpenRouter’s unified-interface benefit without the third-party dependency. Their routing layer supports cost-based, latency-based, and capability-based dispatch out of the box.
The orchestration decision is fundamentally about where you want your dependency. Pure SaaS (OpenRouter, Portkey) gives you reliability and unified billing at the cost of vendor lock-in. Self-hosted (LiteLLM) gives you control at the cost of operational burden. Most mature teams we see end up with LiteLLM as the in-process SDK plus Portkey as the gateway for cross-cutting concerns like budgets and semantic caching — the two complement rather than conflict.
Model routing decisions that actually matter
Here is the routing logic that drives roughly 70% of cost savings in production stacks we have audited:
- Tier by task complexity, not by feature. Classification, extraction, simple summarization → GPT-5.4-nano or Claude Haiku 4.5 (~$0.30–$1 per M tokens). Complex reasoning, code generation, agentic tool use → GPT-5.5 or Claude Opus 4.7. Hard research-grade tasks → GPT-5.5-pro or GPT-5.4-pro.
- Cache aggressively. Both OpenAI and Anthropic now offer prompt caching with 50–90% discount on cached input tokens. Long system prompts and RAG context blocks should be the cached prefix on every call. Cached input on GPT-5.5 costs $0.50/M instead of $5/M.
- Fallback in cost order, not arbitrary order. If Claude Opus 4.7 returns a 529 (overloaded), fall back to GPT-5.5 — not to a weaker model unless the route accepts degraded quality.
- Separate reasoning budgets from response budgets. GPT-5.5 and Claude Opus 4.7 both let you cap reasoning tokens independently. Most production routes do not need 20K reasoning tokens; 2K is usually plenty and 10x cheaper.
Putting the Stack Together: Three Reference Architectures
Fifteen tools is not a stack — it is a shopping list. Below are three coherent stack configurations that work today, scaled by team size and operational tolerance.
The lean startup stack (1–10 engineers)
- Authoring: PromptLayer (hosted, fast to onboard)
- Evals: Promptfoo in GitHub Actions for CI gating, Braintrust free tier for ad-hoc
- Observability: Helicone (proxy, zero-code integration)
- Orchestration: OpenRouter for multi-model access
- Estimated monthly cost (at 5M requests): ~$400 in tooling + model spend
This configuration optimizes for time-to-production. You can stand the whole stack up in under a day and the operational burden is essentially zero. The trade-off is full SaaS dependency and limited customization.
The mid-stage product stack (10–50 engineers)
- Authoring: PromptLayer with schema enforcement, prompt-review workflow via GitHub PRs
- Evals: Braintrust paid tier with golden + drift sets, Promptfoo in CI
- Observability: Helicone or Langfuse self-hosted (your choice on data residency)
- Optimization: DSPy for high-volume structured-output routes
- Orchestration: LiteLLM in-process + Portkey gateway for semantic cache and budgets
- Estimated monthly tooling cost: ~$3K–$8K depending on volume
This is the sweet spot for product teams that have moved past “is it working” and are now optimizing cost, quality, and iteration speed simultaneously. The DSPy investment pays back within 60 days on any route doing more than a million calls a month.
The enterprise / regulated stack (50+ engineers, compliance constraints)
- Authoring: Latitude self-hosted, integrated with internal IAM
- Evals: Promptfoo self-hosted in CI, custom regression harness for domain-specific scoring
- Observability: Langfuse self-hosted with PII redaction at ingest
- Optimization: DSPy in a sandboxed environment with audit logging
- Orchestration: LiteLLM as the only egress path to model providers, with deny-list enforcement
- Estimated monthly tooling cost: minimal SaaS spend, significant headcount cost in platform engineering
The enterprise pattern trades operational simplicity for control. Every tool is self-hosted, every request is auditable, every model call passes through a known egress point. The headcount cost is real — typically two to four platform engineers maintaining this stack full-time — but the alternative (sending regulated data to a SaaS vendor) is often a non-starter.
For a closer look at the tools and patterns covered here, see our analysis in The Complete AI Coding Stack for 2026: 5 Tools Evaluated, which covers the practical implementation details and trade-offs.
What we deliberately left off the list
Several well-known names did not make the 15. Worth a brief mention of why:
- Generic “AI platforms” that bundle everything. Tools that try to be authoring + evals + observability + gateway in one product tend to be mediocre at all four. The teams that win pick best-of-breed per layer and accept the integration cost.
- Hand-rolled prompt-as-code-comment systems. Storing prompts in Python docstrings or YAML files in the same repo as your application code works at very small scale and becomes a liability at any meaningful team size. The lack of independent versioning means model upgrades require code deploys.
- Chrome-extension prompt managers. Fine for individual exploration, not production infrastructure.
- “AI agent builders” that abstract away the prompt entirely. Convenient for prototypes, opaque when something breaks. The teams running these in production almost always end up rebuilding on lower-level primitives within a year.
The
Frequently Asked Questions
What makes prompt engineering tools in 2026 different from 2024?
In 2026, prompts are treated as versioned infrastructure with schemas, typed variables, model bindings, and changelogs. Tools must natively support structured outputs, prompt caching, and multi-step agentic flows introduced by models like GPT-5.5 and Claude Opus 4.7. Treating prompts as opaque strings is now considered legacy architecture.
How has the prompt engineering iteration cycle improved since 2024?
Teams running a proper 2026 tooling stack have reduced the average prompt engineering iteration cycle from 11 hours in 2024 to under 90 minutes. This improvement stems primarily from better tooling — version control, regression testing, observability, and CI/CD pipelines — rather than from model improvements alone.
Why is PromptLayer recommended as a use verdict in 2026?
PromptLayer earns a 'Use' verdict for its Git-style branching, full diff views, A/B prompt routing, and broad model support including GPT-5.5-pro and the full Claude 4.x and Gemini 3.x families. Its request-based pricing keeps costs low for small teams, though its evaluation module is noted as too shallow for production regression suites.
When should a team choose Latitude over a hosted prompt registry?
Latitude is the recommended choice when security requirements prohibit sending prompts to third-party SaaS vendors. As an open-source, self-hostable platform with Terraform-like typed prompt modules, it offers strong data control. The tradeoff is operational overhead, requiring teams to self-manage Postgres, Redis, and a Next.js application.
What are the key pricing details for GPT-5.5 and Claude Opus 4.7?
GPT-5.5, released April 2026 with a 1.05M token context window, is priced at $5 per million input tokens and $30 per million output tokens. Claude Opus 4.7 is priced at $5 per million input tokens and $25 per million output tokens. Both models make prompt caching and structured outputs standard features.
What is the biggest risk of assembling a prompt stack incorrectly?
The primary risk is vendor lock-in combined with high integration costs. Teams that bolt together five disconnected SaaS subscriptions often spend more engineering time on glue code than on core product work. A secondary risk is migration pain when a chosen tool lacks support for new model features like GPT-5.5's structured-reasoning output mode or Claude 4.7's extended caching headers.
Frequently Asked Questions
What makes prompt engineering tools in 2026 different from 2024?
In 2026, prompts are treated as versioned infrastructure with schemas, typed variables, model bindings, and changelogs. Tools must natively support structured outputs, prompt caching, and multi-step agentic flows introduced by models like GPT-5.5 and Claude Opus 4.7. Treating prompts as opaque strings is now considered legacy architecture.
How has the prompt engineering iteration cycle improved since 2024?
Teams running a proper 2026 tooling stack have reduced the average prompt engineering iteration cycle from 11 hours in 2024 to under 90 minutes. This improvement stems primarily from better tooling — version control, regression testing, observability, and CI/CD pipelines — rather than from model improvements alone.
Why is PromptLayer recommended as a use verdict in 2026?
PromptLayer earns a 'Use' verdict for its Git-style branching, full diff views, A/B prompt routing, and broad model support including GPT-5.5-pro and the full Claude 4.x and Gemini 3.x families. Its request-based pricing keeps costs low for small teams, though its evaluation module is noted as too shallow for production regression suites.
When should a team choose Latitude over a hosted prompt registry?
Latitude is the recommended choice when security requirements prohibit sending prompts to third-party SaaS vendors. As an open-source, self-hostable platform with Terraform-like typed prompt modules, it offers strong data control. The tradeoff is operational overhead, requiring teams to self-manage Postgres, Redis, and a Next.js application.
What are the key pricing details for GPT-5.5 and Claude Opus 4.7?
GPT-5.5, released April 2026 with a 1.05M token context window, is priced at $5 per million input tokens and $30 per million output tokens. Claude Opus 4.7 is priced at $5 per million input tokens and $25 per million output tokens. Both models make prompt caching and structured outputs standard features.
What is the biggest risk of assembling a prompt stack incorrectly?
The primary risk is vendor lock-in combined with high integration costs. Teams that bolt together five disconnected SaaS subscriptions often spend more engineering time on glue code than on core product work. A secondary risk is migration pain when a chosen tool lacks support for new model features like GPT-5.5's structured-reasoning output mode or Claude 4.7's extended caching headers.