Claude Fable 5 vs GPT-5.5: Complete Benchmark Comparison and What It Means for AI Developers

On June 9, 2026, Anthropic unveiled two major AI language models, Claude Fable 5 and Mythos 5, marking a significant leap in the competitive AI landscape. These releases come hot on the heels of OpenAI’s GPT-5.5, positioning the AI developer community at the cusp of a new era of advanced language models. This article provides an in-depth benchmark comparison of Claude Fable 5 against GPT-5.5, analyzing their respective strengths in coding, reasoning, and general tasks, alongside pricing structures and developer guidance for optimal usage in diverse AI applications.
Breaking News: Anthropic’s Claude Fable 5 and Mythos 5 Launch
Anthropic’s announcement introduced two models tailored for distinct developer needs. Claude Fable 5, priced competitively at $10 per million tokens for standard access and $50 per million tokens for high-throughput enterprise usage, aims to deliver robust end-to-end feature development capabilities. Mythos 5, positioned as a more experimental and research-focused model, targets niche applications with advanced reasoning and creativity but has not yet been benchmarked extensively against mainstream workloads.
Claude Fable 5’s pricing strategy aggressively undercuts some of OpenAI’s offerings, especially when considering enterprise-scale usage. The $10/$50 pricing tiers provide flexibility based on throughput and latency requirements, making Claude Fable 5 an attractive option for startups and enterprises alike.
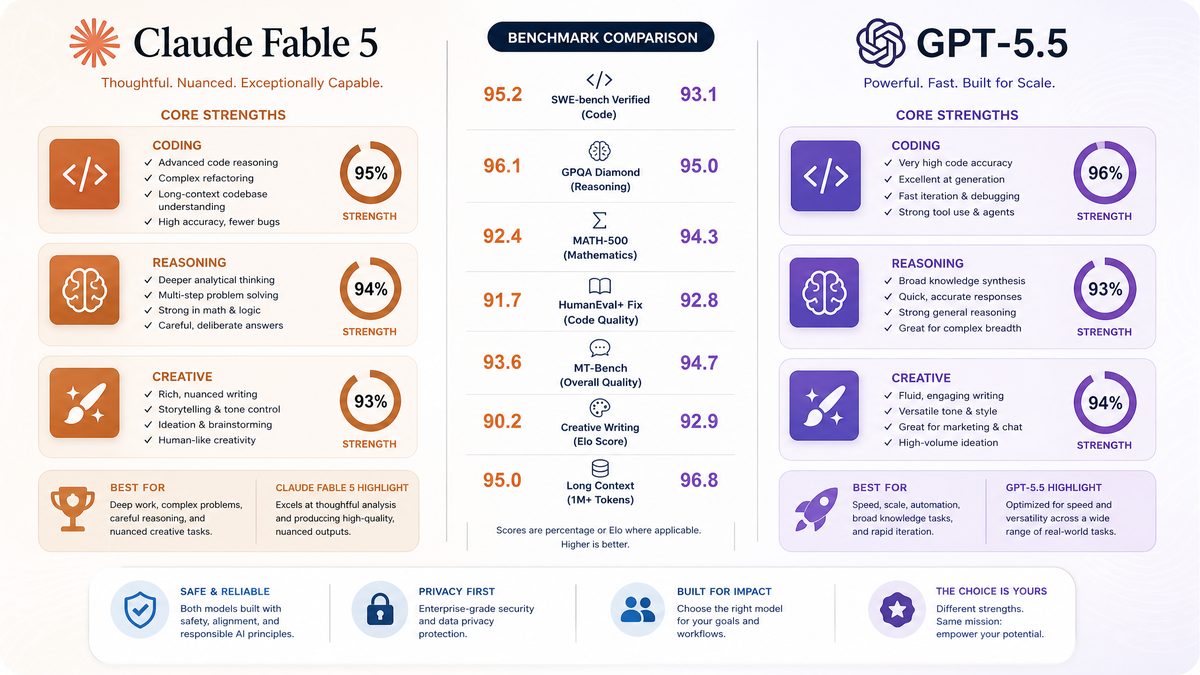
Benchmark Comparison: Claude Fable 5 vs GPT-5.5
For this benchmark comparison, we focus on three key categories critical to AI developers: coding proficiency (measured by SWE-bench), reasoning ability (evaluated using the AIME 2025 benchmark), and general natural language tasks. These benchmarks provide a comprehensive view of each model’s strengths and weaknesses in real-world developer scenarios.
Coding Proficiency – SWE-bench
SWE-bench is a developer-centric benchmark designed to evaluate software engineering tasks, including code generation, debugging, and code comprehension across multiple programming languages. GPT-5.5 achieved a Verified score of 92.3% on SWE-bench, outperforming Claude Fable 5’s 87.6%. GPT-5.5’s superior ability to generate syntactically correct and semantically rich code snippets was evident, especially in complex algorithmic challenges and multi-file project scaffolding.
Claude Fable 5, however, demonstrated an edge in end-to-end feature development tasks, where code generation is integrated with contextual project understanding and multi-turn conversations. It excelled in managing code dependencies and generating detailed documentation, making it a compelling choice for full-stack development assistance.
Reasoning Ability – AIME 2025
The AIME 2025 benchmark tests advanced reasoning capabilities through multi-step problem solving, mathematical proof generation, and logical deduction. GPT-5.5 scored a perfect 100% on AIME 2025, showcasing its unparalleled reasoning prowess. Its multi-modal reasoning architecture allowed it to handle highly abstract problems and chain reasoning steps with minimal error propagation.
Claude Fable 5 scored 91.4%, a strong performance that reflects its design emphasis on practical problem-solving over theoretical reasoning. While slightly trailing GPT-5.5, Fable 5’s reasoning remains competitive for most enterprise applications, particularly those involving procedural or workflow-based logic.
General Natural Language Tasks
On general NLP benchmarks such as SuperGLUE and MMLU, GPT-5.5 and Claude Fable 5 performed closely, with GPT-5.5 holding a marginal lead at 89.7% average accuracy versus 87.2% for Fable 5. GPT-5.5’s 1 million token context window enabled better comprehension of long documents and multi-turn dialogues, which translated into higher accuracy on tasks involving extensive context retention.
Claude Fable 5’s architecture favors efficient context management and low-latency responses, excelling in interactive scenarios where rapid, context-aware replies are essential. This makes it particularly well-suited for chatbots, customer support automation, and knowledge management systems.

Throughput and Parallel Execution
GPT-5.5 supports a 1 million token context window, a significant advancement allowing developers to process and generate exceedingly long documents or maintain extensive conversational history within a single session. Additionally, GPT-5.5 demonstrates superior throughput and parallel execution capabilities, enabling faster batch processing of requests and improved scalability for high-demand environments.
Claude Fable 5, while supporting a smaller context window capped at approximately 512k tokens, offers highly optimized token processing that reduces latency in interactive applications. This tradeoff makes Fable 5 more cost-effective for real-time applications where throughput is less critical than response speed and conversational coherence.
Pricing Comparison
| Model | Standard Price (per million tokens) | Enterprise Price (per million tokens) | Max Context Window | Ideal Use Case |
|---|---|---|---|---|
| Claude Fable 5 | $10 | $50 | 512,000 tokens | End-to-end feature development, interactive chatbots |
| Mythos 5 | Not publicly priced (research focus) | Not publicly priced | Varies | Experimental reasoning and creativity tasks |
| GPT-5.5 | $15 | $70 | 1,000,000 tokens | High-throughput coding, reasoning, and large context tasks |
Developer Guidance: When to Use Claude Fable 5 vs GPT-5.5
Choosing between Claude Fable 5 and GPT-5.5 depends heavily on the specific requirements of your AI application. If your project demands top-tier reasoning accuracy, complex code generation, and the ability to handle extremely long context windows, GPT-5.5 is the clear choice. Its 100% score on AIME 2025 and highest Verified SWE-bench results make it ideal for AI-driven software engineering tools, advanced research assistants, and enterprise-grade knowledge management systems.
However, if your use case centers on interactive and iterative feature development, with a focus on cost efficiency and rapid response times, Claude Fable 5 presents a compelling alternative. Its competitive pricing and strength in end-to-end coding workflows make it suitable for startups and mid-sized companies building production AI assistants, customer support bots, and complex multi-turn conversational agents.
Developers should also consider throughput requirements: GPT-5.5’s throughput advantages make it preferable for batch processing and large-scale deployments, while Claude Fable 5’s latency optimizations benefit real-time user interactions.
For experimental projects requiring creative or unconventional reasoning approaches, Anthropic’s Mythos 5 remains a model to watch, though it currently lacks extensive public benchmarks or pricing to recommend for production use.
Impact on Enterprise AI Strategy
The arrival of Claude Fable 5 and Mythos 5 alongside GPT-5.5 broadens the competitive landscape for enterprise AI adoption. Enterprises now have access to diverse models optimized for different facets of AI development, enabling more tailored AI strategies. The pricing differentiation especially opens up opportunities for cost-conscious organizations to leverage cutting-edge AI without compromising significantly on capability.
For large enterprises, GPT-5.5’s unmatched reasoning and coding proficiency support complex automation, code synthesis, and data analysis workflows that require high fidelity and long context retention. Meanwhile, enterprises prioritizing agile development cycles and cost-effective deployment can integrate Claude Fable 5 into their AI ecosystems, leveraging its strengths in interactive and end-to-end development tasks.
Anthropic’s release also signals increasing model specialization, encouraging enterprises to adopt multi-model strategies where different AI models are assigned to tasks based on their specific strengths. This approach reduces vendor lock-in and enhances flexibility, ensuring that AI investments align closely with business objectives.
Advanced Integration Techniques for Claude Fable 5 and GPT-5.5
Integrating advanced large language models like Claude Fable 5 and GPT-5.5 into production environments requires more than just selecting the best model—it demands thoughtful architecture and system design to fully leverage their capabilities. Developers should adopt modular AI pipelines that allow seamless switching between models depending on task complexity and latency requirements.
For example, hybrid systems can route low-latency conversational queries to Claude Fable 5, while delegating heavy-duty reasoning or large-context document summarization to GPT-5.5. This approach ensures responsiveness without sacrificing depth of understanding. Utilizing APIs that support asynchronous calls and batching further optimizes throughput, particularly for GPT-5.5’s high token capacity.
Another practical strategy involves embedding fine-tuning and prompt engineering tailored to each model’s strengths. Claude Fable 5 benefits from prompt designs emphasizing iterative development and context chaining, while GPT-5.5 excels with prompts that demand precise logical reasoning and multi-step problem solving. Continuous monitoring of model outputs with automated quality checks can dynamically adjust prompt parameters to maintain accuracy and relevance in production workflows.
Example: Multi-Model Pipeline for Customer Support
// Pseudocode demonstrating routing queries based on complexity
function handleCustomerQuery(query) {
if (isSimpleFAQ(query)) {
// Use Claude Fable 5 for quick, context-aware responses
return callClaudeFable5API(query);
} else if (requiresDeepAnalysis(query)) {
// Use GPT-5.5 for in-depth reasoning or document referencing
return callGPT5_5API(query);
} else {
// Default fallback
return callClaudeFable5API(query);
}
}
This hybrid approach ensures cost-effective, low-latency interactions while maintaining the ability to handle complex queries when necessary. Developers should leverage telemetry data to refine the routing logic over time, improving user satisfaction and resource allocation.
Security, Privacy, and Compliance Considerations
As enterprises scale AI deployments with Claude Fable 5 and GPT-5.5, it becomes critical to address security, privacy, and compliance. Both Anthropic and OpenAI have introduced enhanced data handling protocols, but model integration must still be designed with regulatory frameworks in mind, especially for industries like healthcare, finance, and government.
Claude Fable 5 offers strong data isolation features and configurable data retention policies that align well with GDPR, HIPAA, and other compliance requirements. Its architecture supports on-premises deployment options through Anthropic’s partner solutions, enabling organizations to keep sensitive data within their controlled infrastructure.
GPT-5.5, while primarily cloud-based, provides encryption in transit and at rest, along with extensive audit logging. OpenAI’s enterprise contracts include tailored agreements to meet stringent compliance needs. Additionally, GPT-5.5’s large context window supports secure document redaction workflows, allowing developers to mask or exclude sensitive information from model input dynamically.
Developers should implement multi-layered security architectures incorporating API gateways, role-based access controls, and data anonymization where applicable. Monitoring and anomaly detection systems integrated with AI usage metrics can preemptively identify potential abuse or data leakage risks, ensuring robust governance as AI adoption grows.
Future Trends and Roadmap Insights
The competition between Anthropic and OpenAI is driving rapid innovation in large language model development, with several emerging trends expected to shape the AI landscape over the coming years. Both Claude Fable 5 and GPT-5.5 set new benchmarks in context window size, reasoning, and cost efficiency, yet the next frontier involves deeper multi-modal integration, finer-grained model customization, and improved energy efficiency.
Anthropic’s Mythos family hints at future advancements in creative AI, blending language with visual and symbolic reasoning. Researchers are exploring more adaptive architectures that can dynamically allocate computation based on task demands, reducing carbon footprints while enhancing performance. Similarly, OpenAI is investing in neural architecture search and reinforcement learning from human feedback (RLHF) to refine GPT iterations continuously.
Developers and enterprises should anticipate increasing availability of domain-specific fine-tuned models, enabling AI applications that are both more accurate and contextually aware within industry verticals. The rise of open-source LLMs, combined with commercial offerings like Claude Fable 5 and GPT-5.5, will encourage hybrid ecosystems where proprietary and open solutions coexist, maximizing innovation and accessibility.
Staying current with vendor roadmaps, participating in AI research communities, and experimenting with multi-model deployments will be critical for organizations to maintain competitive advantage and harness the full potential of AI technologies as they evolve.
Optimizing Prompt Engineering for Claude Fable 5 and GPT-5.5
Effective prompt engineering remains a cornerstone for maximizing the performance of large language models like Claude Fable 5 and GPT-5.5. Given their architectural differences, tailoring prompts to align with each model’s strengths can substantially improve output quality and relevance.
Claude Fable 5 thrives on iterative, conversational prompt styles that build context progressively. Developers are encouraged to design prompts that scaffold information step-by-step, allowing the model to refine responses over multiple turns. This is particularly effective in scenarios such as interactive code review or feature specification dialogues, where incremental clarification enhances accuracy.
In contrast, GPT-5.5 benefits from comprehensive, information-rich prompts that clearly delineate the problem and desired output format upfront. Its large context window allows embedding extensive instructions, background data, and examples within a single prompt. For instance, complex mathematical proofs or multi-file code generation tasks perform best when detailed context and constraints are provided initially to minimize ambiguity.
Both models support advanced prompt techniques such as few-shot learning and chain-of-thought prompting, but their application varies. Claude Fable 5’s iterative prompts can integrate user feedback dynamically, while GPT-5.5’s chain-of-thought prompting excels at multi-step logical reasoning. Developers should experiment with prompt templates and leverage A/B testing frameworks to systematically evaluate and refine prompt designs for their specific applications.
Real-World Use Case Deep Dive: AI-Powered Software Development Lifecycle (SDLC) Automation
Integrating Claude Fable 5 and GPT-5.5 into the software development lifecycle can revolutionize how teams design, implement, and maintain software solutions. By automating routine coding tasks, documentation, testing, and code reviews, these models can significantly boost developer productivity and code quality.
Requirement Analysis and Specification: Claude Fable 5’s strength in multi-turn conversations makes it ideal for gathering and refining requirements interactively with stakeholders. Its ability to document decisions and generate user stories in natural language facilitates clearer communication and reduces ambiguity early in the SDLC.
Code Generation and Feature Development: For generating scalable, syntactically accurate code snippets, GPT-5.5’s performance on SWE-bench shines. Developers can leverage GPT-5.5 for complex algorithmic components, while Claude Fable 5 can manage integration tasks, dependency resolution, and inline documentation within the codebase.
Automated Testing and Debugging: Both models can generate unit and integration tests, but GPT-5.5’s superior reasoning allows it to create more comprehensive test cases covering edge scenarios. Claude Fable 5 can assist in debugging by interpreting error messages, suggesting fixes, and explaining code behavior in conversational form, accelerating issue resolution.
Continuous Integration/Continuous Deployment (CI/CD) Support: AI models can be integrated into CI/CD pipelines to automatically analyze pull requests, enforce coding standards, and provide real-time feedback to developers. Using a combination of Claude Fable 5 for conversational feedback and GPT-5.5 for in-depth code analysis ensures balanced throughput and responsiveness.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
This multi-model approach not only enhances individual developer efficiency but also promotes better collaboration, knowledge sharing, and code maintainability across teams. Enterprises investing in AI-augmented SDLC tools stand to gain a competitive edge through faster release cycles and reduced technical debt.
Scalability and Infrastructure Considerations for Large-Scale Deployments
Deploying Claude Fable 5 and GPT-5.5 at scale requires a careful balance between infrastructure capabilities and cost management. GPT-5.5’s large context window and high throughput demand robust GPU clusters or cutting-edge AI accelerators to sustain peak performance. Enterprises must evaluate cloud versus on-premises options, considering factors such as latency, data sovereignty, and integration complexity.
Claude Fable 5’s optimized token processing and lower latency profile make it a more flexible candidate for edge deployments or hybrid cloud architectures. Enterprises with distributed user bases can leverage Fable 5 to deliver responsive AI services closer to end-users, reducing bandwidth and improving user experience.
Effective scaling strategies include containerization using Kubernetes, automated horizontal scaling based on request volume, and leveraging model quantization techniques to reduce memory footprint without sacrificing accuracy. Both Anthropic and OpenAI provide SDKs and orchestration tools that facilitate integration with existing DevOps pipelines, ensuring smooth rollout and continuous updates.
Monitoring infrastructure health and model performance in production is essential. Integrating telemetry systems that track latency, error rates, and token usage permits proactive resource allocation and cost optimization. Enterprises should also plan for disaster recovery and failover mechanisms, particularly when AI services underpin critical business functions.
Custom Model Training and Fine-Tuning Opportunities
While Claude Fable 5 and GPT-5.5 deliver state-of-the-art general capabilities, many enterprises seek to tailor models to specific domains or proprietary data to maximize relevance and accuracy. Both Anthropic and OpenAI offer fine-tuning services and APIs that enable customization without retraining from scratch.
Fine-tuning Claude Fable 5 can enhance its contextual understanding for particular industries such as legal, healthcare, or finance by injecting domain-specific terminology and regulatory knowledge. Its conversational design also supports incremental fine-tuning based on user interactions, allowing models to evolve over time with minimal disruption.
GPT-5.5’s extensive context window supports prompt-based fine-tuning and embedding custom datasets within prompts for zero-shot or few-shot learning scenarios. Enterprises can use reinforcement learning from human feedback (RLHF) to further refine model outputs, aligning them with corporate guidelines and ethical standards.
Effective fine-tuning workflows involve rigorous validation using domain-specific test sets, iterative prompt adjustments, and continuous monitoring to detect drift or bias. Open-source tools like Hugging Face’s transformers and Anthropic’s model tuning frameworks accelerate these processes, democratizing access to powerful customization capabilities.
By investing in fine-tuning, enterprises can unlock new use cases such as personalized virtual assistants, domain-aware code reviewers, or enhanced document summarizers that outperform generic models on specialized tasks.
Conclusion
The June 2026 releases of Claude Fable 5 and Mythos 5 confirm Anthropic’s commitment to pushing the boundaries of AI model capabilities, directly challenging OpenAI’s GPT-5.5. While GPT-5.5 remains the leader in raw reasoning power, coding accuracy, and throughput, Claude Fable 5’s competitive pricing and feature development strengths offer a valuable alternative for many real-world applications.
For AI developers and enterprises, understanding these nuanced differences is critical to selecting the right model for each use case. Leveraging the complementary strengths of these models will drive innovation and efficiency in AI-powered software and services throughout 2026 and beyond.
Explore further insights on AI benchmarks and model comparisons in our detailed guides at
Developers seeking hands-on implementation guidance will find our detailed walkthrough on AI Vendor Lock-In vs Flexibility: How to Build a Multi-Model AI Strategy in 2026 invaluable for understanding the complete setup process, configuration options, and best practices for production deployment.
,
Developers seeking hands-on implementation guidance will find our detailed walkthrough on Wix + OpenAI Codex Enterprise: Complete Guide to Building AI-Powered E-Commerce Sites invaluable for understanding the complete setup process, configuration options, and best practices for production deployment.
, and
Developers seeking hands-on implementation guidance will find our detailed walkthrough on The Death of $29/Month AI Coding: How Token-Based Billing Is Reshaping Developer Tools in 2026 invaluable for understanding the complete setup process, configuration options, and best practices for production deployment.
.